
What Is SEO?
SEO (search engine optimization) is a set of processes aimed at improving a website’s visibility in search engines, like Google, with the goal of getting more organic traffic. SEO is about fulfilling users’ search needs by creating relevant, high-quality content and providing the best possible user experience.

SEO activities can take place both on-site and off-site. That’s why you may often see SEO divided into “on-page” and ”off-page” categories.
In practice, SEO typically involves:
- Keyword research
- Content creation and optimization
- Technical optimization
- Link building
Why Is SEO Important?
Every day, Google users conduct billions of searches for information and products. It’s no surprise that search engines are usually one of the biggest traffic sources to websites.
To harness this traffic source’s potential, you need to appear in the top search results for your target keywords.
The correlation is very simple—the higher you rank, the more people will visit your page.
The No. 1 organic result is 10x more likely to receive a click than a page ranking in position No. 10.
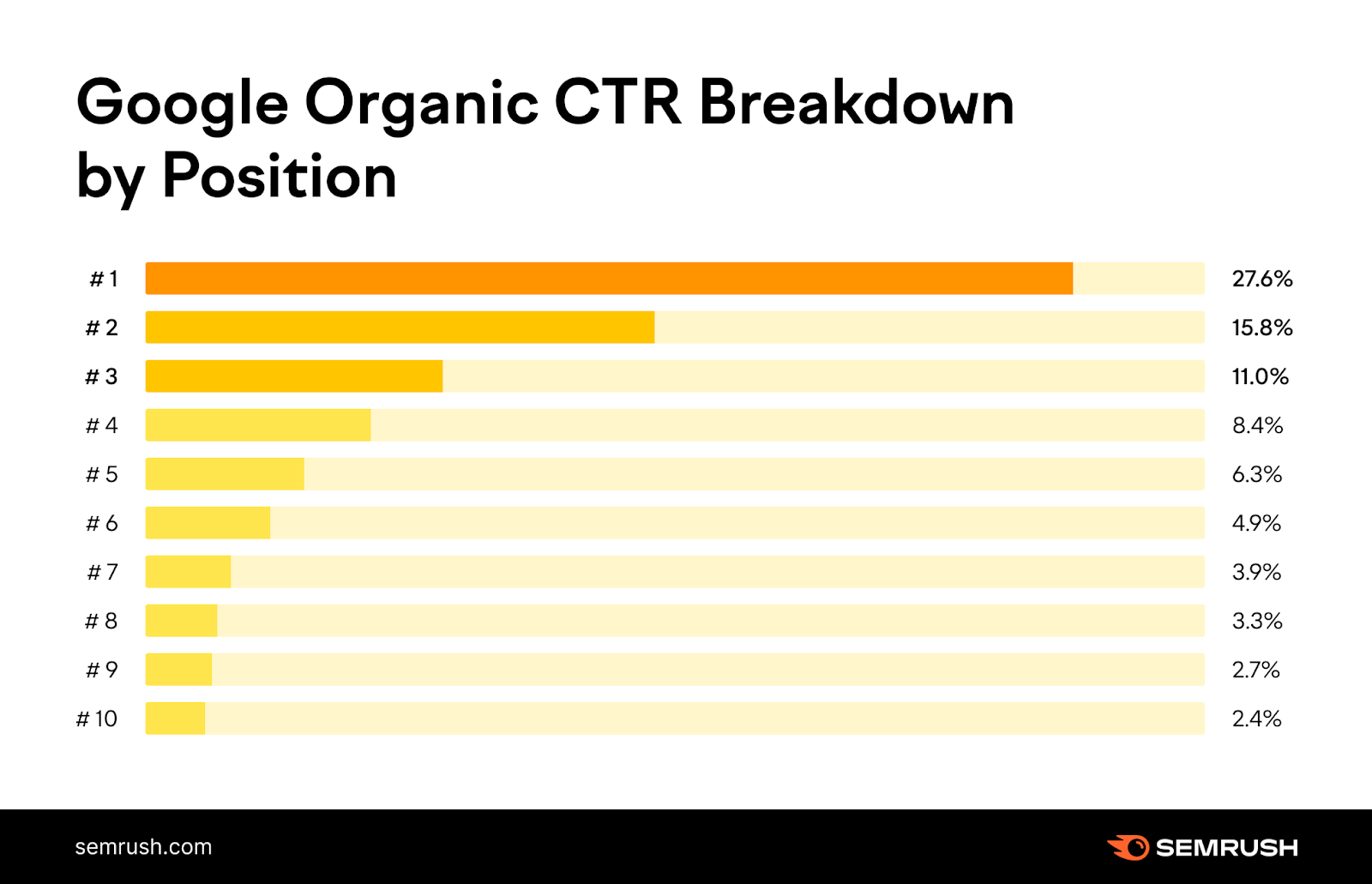
And the top three organic results get more than 50% of all the clicks.
This is where SEO enters the picture.
Search engine optimization plays a key role in improving your ranking positions. Better rankings mean more traffic. And more traffic means new customers and more brand awareness.
In other words, neglecting SEO would mean neglecting one of the most important traffic channels—leaving that space completely to your competitors.
SEO vs. PPC
Most search engine results pages (SERPs) contain two main types of results:
- Paid results: You have to pay to be here, through pay-per-click (PPC) advertising
- Organic results: You must “earn” your rankings here, through SEO
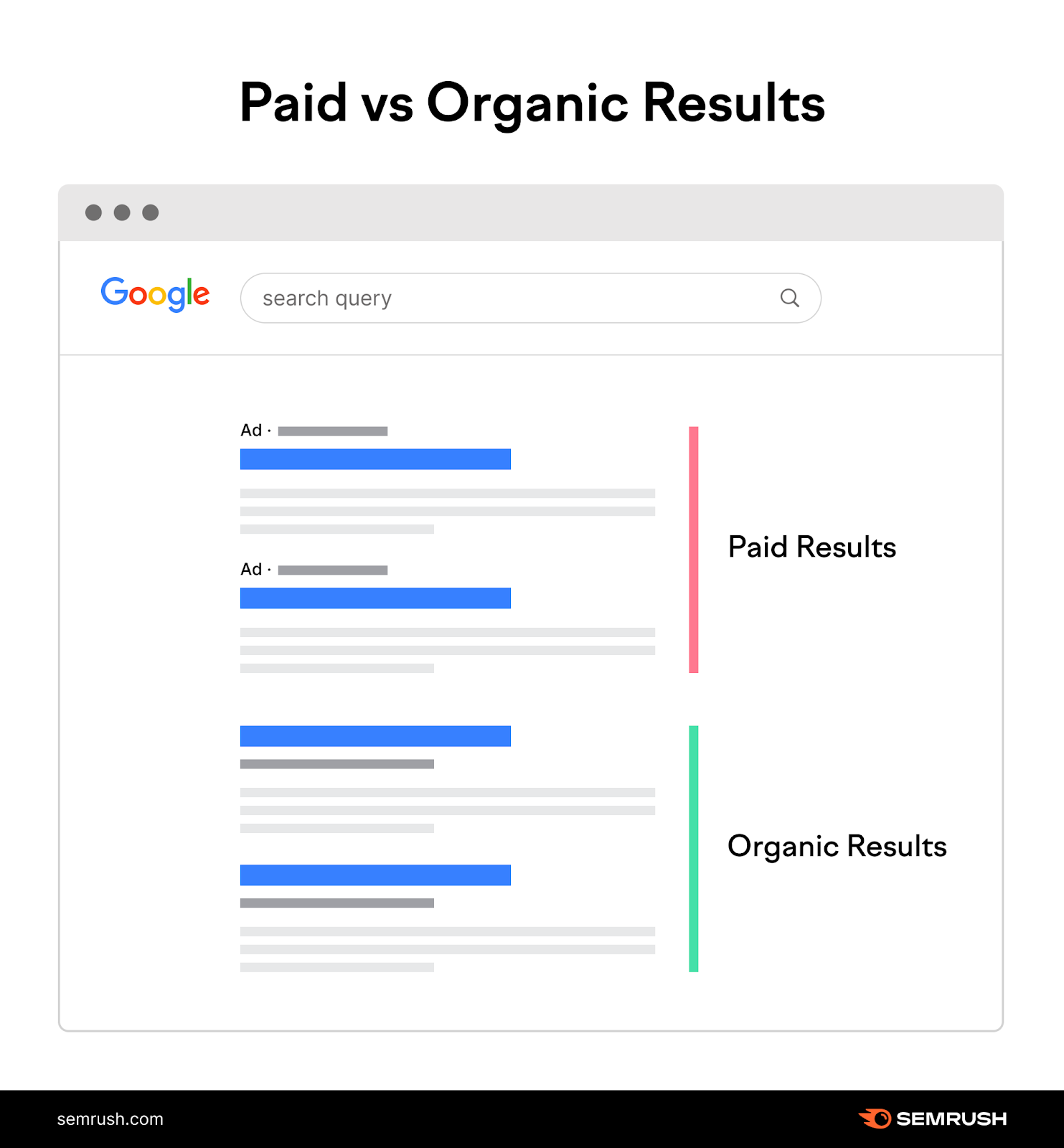
You may ask: Why not just pay to appear in the ads section?
The answer is simple. The vast majority of people just ignore ads and click on the organic results instead.
Yes, SEO takes more time, effort, and—although it focuses on “free” organic traffic—resources.
But once you rank for your target keywords, you can reach more people and generate “passive” traffic that doesn’t disappear the moment you stop paying.
Note: Need to set up a Google Ads campaign? Our PPC Keyword Tool offers a quick and easy way to set up a campaign, organize keywords, set negative keywords, and export everything into the Google Ads editor.
How Do Search Engines Work?
The ultimate goal of any search engine is to make searchers happy with the results they find.
To achieve this, search engines need to find the best pages. And serve them as the top search results.
Note: Google is not the only search engine. But it is by far the most popular one. That’s why we refer to Google most times we talk about search engines. Besides, SEO fundamentals are fairly similar across most search engines.
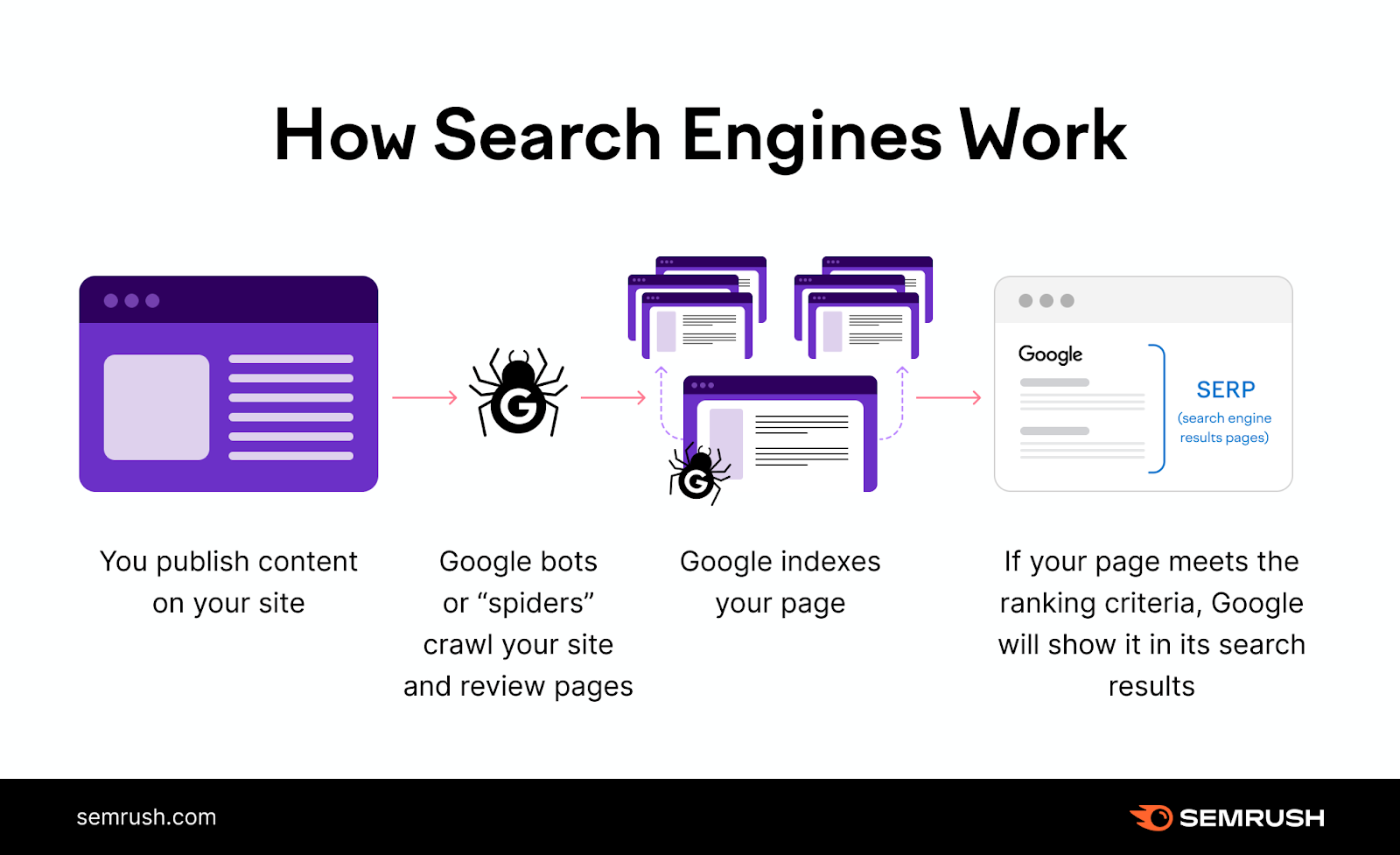
Google uses the following stages to find and rank content:
- Crawling: Google uses “bots,” or computer programs, to crawl the web and look for new or updated pages. In order for Google to find a page, the page should have at least one link pointing to it.
- Indexing: Next, Google analyzes each page and tries to make sense of what the page is about. Then, it may store this information in the Google Index—a huge database of webpages.
- Serving results: When a user enters a query, Google determines which pages are the best, in terms of both quality and relevance, and ranks them in the SERP.
Your job as a website owner is to help search engines crawl and index all the pages on your site that you want them to. (And none of them that you don’t.)
You can ensure the crawlability and indexability of your pages through a number of actions and best practices commonly referred to as technical SEO.
Now that you understand how Google finds and categorizes pages, it’s time to take a closer look at how the top results are selected. And the role of SEO in this process.
Further reading:
How Does SEO Work?
Google uses relatively complex processes, known as “algorithms,” to rank pages.
These algorithms take into account a huge number of ranking factors to decide where a specific page should rank.
You don’t need to know how search algorithms work. (Actually, nobody does with 100% certainty.)
However, knowing the basics can help you better understand how SEO works and what it takes to optimize your pages to rank in Google.
Ensuring Relevance
Your No. 1 job in SEO is to ensure that you're offering relevant content.
Why?
Because Google’s No. 1 job is to show users relevant results.
Relevance is much more than just showing pages about dogs, not cats, when someone searches for “dogs.”
It is also about satisfying the user’s search intent—the reason why they used a particular search query.
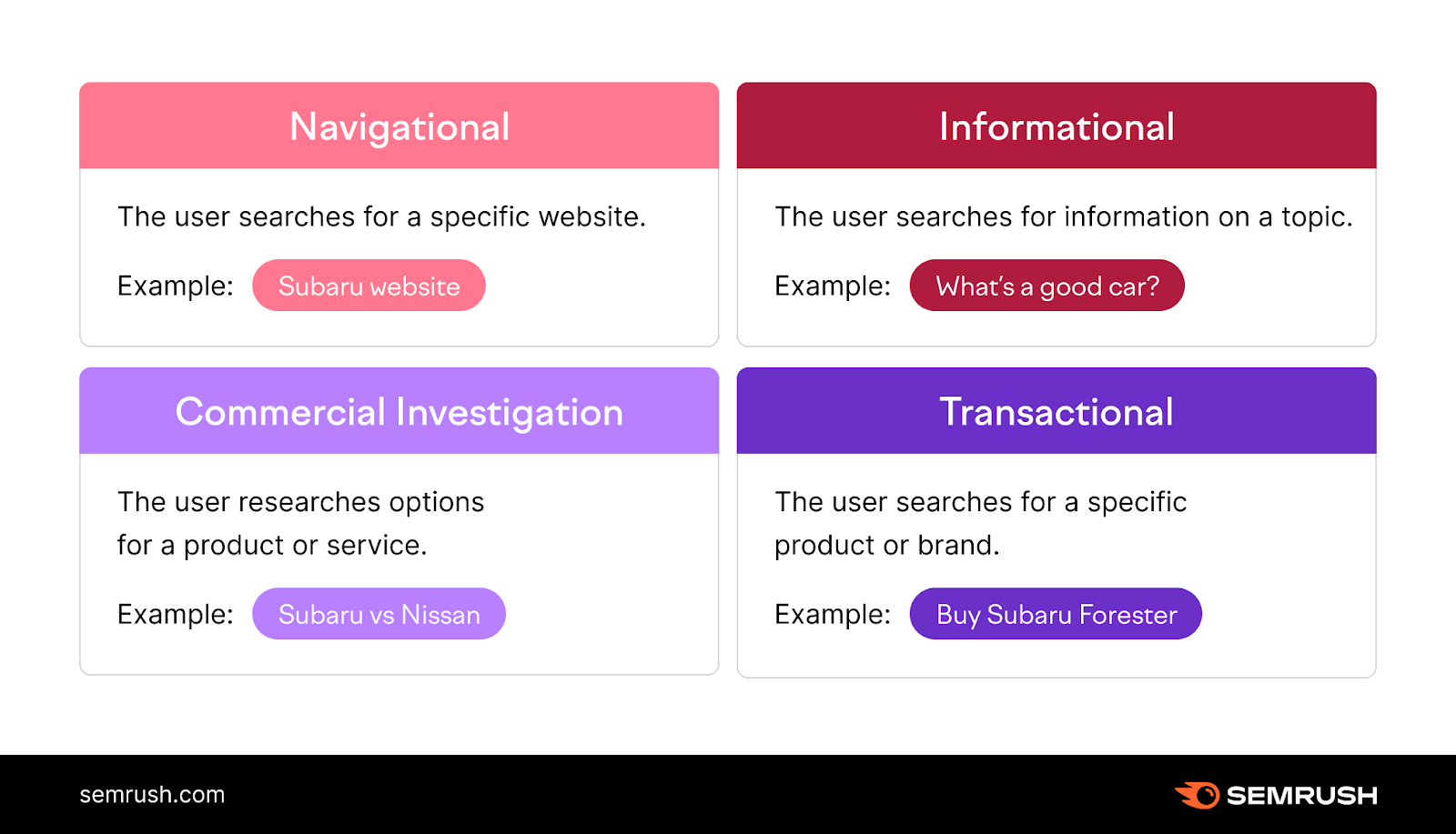
There are four main types of search intent:
- Navigational (e.g., “spotify login”)
- Informational (e.g., “what is spotify”)
- Commercial (e.g., “spotify review”)
- Transactional (e.g., “spotify premium”)
Here’s an example:
If you search for “best dog food,” you don’t want to see articles about different types of dog diets or recipes for homemade dog food. Both would be topically relevant, but they do not fulfill your search intent.
Google knows, based on the behavior of millions of other users, that if you search for “best dog food,” you almost certainly want to buy dog food.
That’s why Google ranks either product pages or reviews of the best dog food products (i.e., the search intent is either transactional or commercial).

So, how do you make sure your page fulfills the intent behind a search query?
Luckily, Google does all the hard work. All you need to do is look at the search results and analyze what you see.
Things you need to consider to create relevant content:
- Topical relevance: One of the ways Google determines a page’s topic is by looking at the keywords that appear on the page. Optimize your pages for keywords, but avoid overdoing it.
- Type of content: Make sure your page provides the right type of content for the query by looking at what types of results rank for the keyword (e.g., landing pages, product pages, informational posts, reviews, etc.)
- Content freshness: Some types of topics, such as news updates or product reviews, require fresh, frequently updated information. If the search query is time-sensitive, you need to ensure your content will also stay up to date.
- Location: Google may serve different results based on a searcher’s location. If this is the case, you need to adjust your strategy accordingly (e.g., if you run a local business, follow local SEO best practices).
Where to Start?
To quickly identify a keyword’s intent, use a tool like Keyword Overview.
Enter your keyword and click “Search.”

You’ll see the intent in the widget labeled “Intent.”

And if you’re doing keyword research, the Keyword Magic Tool also displays intent.
Like this:

Further reading:
Creating Quality Content
Finding the right keywords is just the first step.
You also need to create content that will rank for those keywords. Content creation and optimization are two irreplaceable parts of SEO.
When asked about the most important factor to rank in the top search results, John Mueller of Google answered with a single word:
@methode @JohnMu What's the main important factor for rank a website in top search results on a particular phrase?
— Saroj Kumar (@sarojnishad) September 6, 2017
To rank well in Google, you need to create content that is literally among the top 10 pieces on a given topic.
There are 10 organic results on the first page of each SERP, and that’s where you want to be.
Here are a few key things that separate high-quality content from mediocre content:
- Comprehensiveness: Cover the topic thoroughly and answer all the questions a visitor might have. It’s not about word count. Ensure that each page gives searchers a complete resource.
- Uniqueness: Your content should not be a compilation of the top results. It should always provide some added value—whether it is a unique angle, useful data, helpful examples, or original visuals.
- E-E-A-T signals: Google pays a lot of attention to Experience, Expertise, Authoritativeness, and Trustworthiness (E-E-A-T). You should provide accurate and reliable information, be an expert on what you write about, and demonstrate it both on-site and off-site.
- Readability: Your text should be easy to read. This includes structuring your content logically, writing short sentences, avoiding passive voice, having a consistent tone of voice, etc.
Where to Start?
Once you’ve conducted keyword research, it’s time to start creating content.
It’s difficult to measure the quality of content exactly, but a tool like SEO Writing Assistant can help.
To start, open the tool and start writing. Or, if you already have the text, copy and paste it in.
The tool will evaluate your content in four categories—”Readability,” “SEO,” “Originality,” and “Tone of Voice”—and suggest improvements.
Like so:

Providing Great Usability
Google prefers user-friendly websites.
Technical SEO plays an important role here again. Besides ensuring the crawlability and indexability of your website, SEO also makes sure your website meets usability standards.
This includes factors like:
- Site security: Your website should meet standard security criteria, like having an SSL certificate (using HTTPS protocol instead of HTTP).
- Page speed: Google ranks faster pages higher in the search results because they provide a better user experience.
- Mobile friendliness: Google evaluates your content based on its performance on a mobile device—this is called “mobile-first indexing.” Mobile SEO ensures that mobile users are able to consume your content easily.
- Ease of use: You should have an easy-to-follow website structure that allows visitors to find everything quickly. And navigate through your site without any problems or obstructions.
Where to Start?
The best way to get a general overview of your website’s usability is to run a complete site audit.
In Semrush’s Site Audit, you'll find several reports that focus on different aspects of your website’s performance.
Start by entering your domain and clicking “Start Audit.”

In the basic settings, select the number of pages per audit and the crawl source as “Website.”
Then, click “Start Site Audit.”

Once the tool is done crawling your site, you’ll see a dashboard with your site’s overall health. And different thematic reports.

Besides checking for over 140 issues, the tool also provides recommendations on how to fix them.
Like this:
Head to the “Issues” tab and you’ll see all of your site’s errors, warnings, and notices.

To learn more about the issue and how to fix it, click “Why and how to fix it” and you’ll see a popup.

Further reading:
Building Authority
Search engines use several off-page signals to determine whether your site can be trusted.
One of the strongest signals, and one of the strongest ranking factors in general, is backlinks—links from other websites pointing to your site.
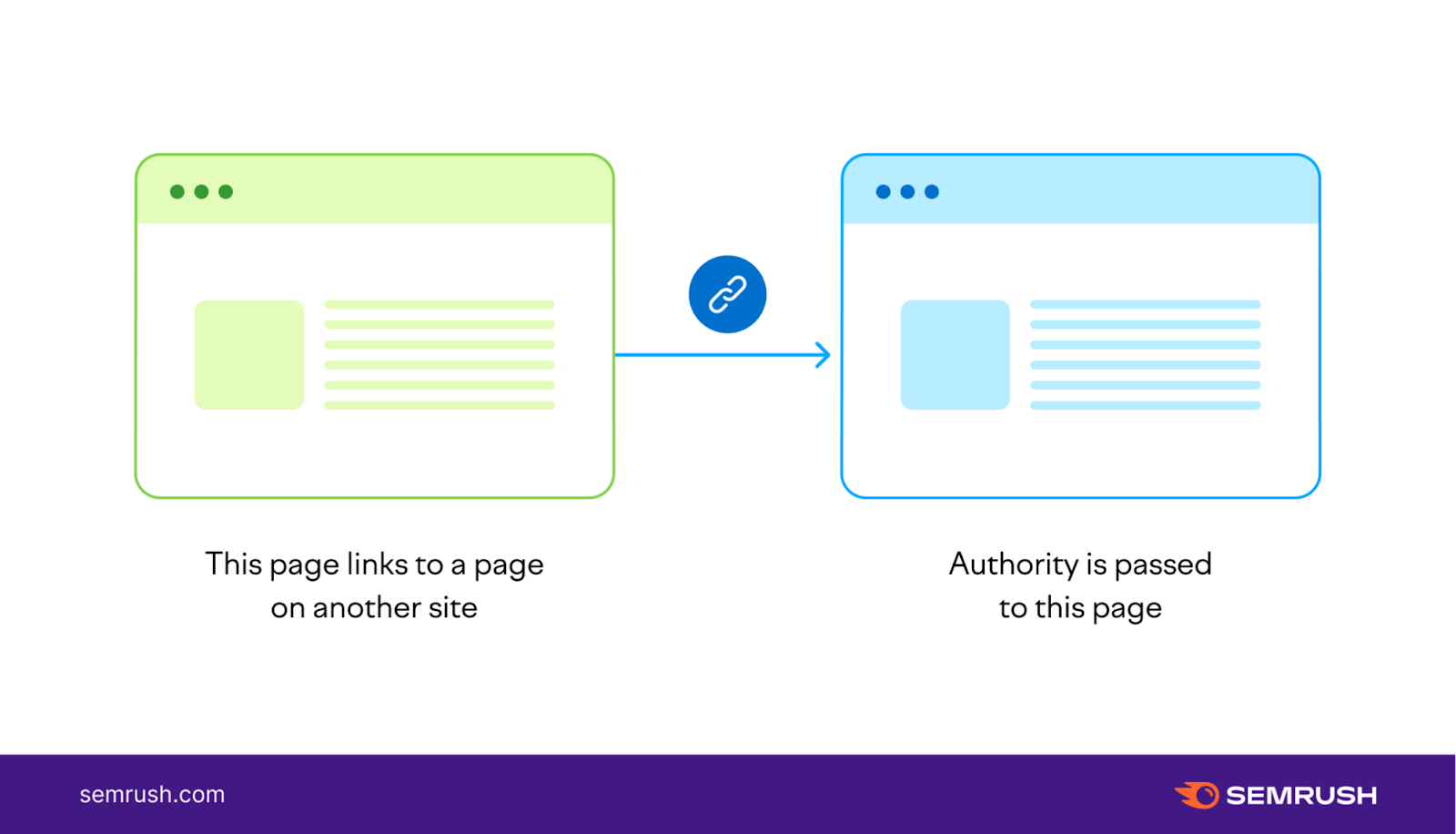
Essentially, backlinks function as votes of confidence to search engines.
In general, the more high-quality links your page receives, the more authority your page has in the eyes of Google. Which can lead to higher rankings.
That’s why link building—the practice of getting backlinks to your site—is an important part of SEO.
There are plenty of link building strategies. For example:
- Creating linkable assets: creating content that provides great value and naturally attracts links (e.g., original studies, interactive pages, free tools)
- Guest blogging: writing posts for other websites in order to link back to your website
- Broken link building: finding links that no longer work on other websites and suggesting links to your pages as replacements
Tip: Learn more about the best ways to get backlinks in our link building guide for beginners.
Focus on quality (not quantity) when building links.
A single backlink from a high-authority page will pass more authority than 100 backlinks from irrelevant, low-quality pages.
Yes, you do want as many links as possible. But those links need to be from relevant, quality pages related to your site’s topic.

Last thing to remember:
Although Google ranks pages, not websites (meaning they evaluate most authority signals at a page level), the overall number of backlinks to your website can still influence a particular page’s rankings.
How?
Through internal linking (linking from one page of your website to another), you can pass authority between your pages the same way it passes from external pages to your site.
Keep this in mind when creating internal links. And make sure your most important pages have enough internal links pointing at them.
As Google’s John Mueller said about internal linking: “[It is] one of the biggest things that you can do on a website to kind of guide Google and guide visitors to the pages that you think are important.”
Where to Start?
The easiest way to find backlink opportunities is to run a backlink gap analysis.
Why?
It’ll help you see the sites linking to your competitors, but not to you.
After all, if a site is happy to link to a competitor, they’ll probably be happy to link to you, too.
Especially if you create higher-quality content.
To start, head to the Backlink Gap tool.
Then, enter your domain and up to four competitor domains. And click “Find prospects.”

You’ll get a table with all the websites that have backlinks to your competitors.

And you have different filters: “Best,” “Weak,” “Strong,” “Shared,” “Unique,” or “All” opportunities.

Here’s what each filter means:
- Best: Websites that link to all of your competitors, but not to you
- Weak: Websites that link to you less than to competitors
- Strong: Websites that link only to you
- Shared: Websites that link to all of your competitors
- Unique: Websites that link to only one competitor domain
- All: All prospective websites
Start with the “Best” filter. Hit the “Export” button on the top right.

And you now have a long list of sites you can reach out to for backlinks.
7 Truths About SEO
So that’s what SEO means in practice.
But here are seven truths you should take to heart before embarking on your SEO journey:
- SEO is not about cheating Google. Instead, think of it as convincing Google to rank your page by showing the value you provide for users.
- SEO is not about hacks. Don’t get caught in a loop of looking for cool new SEO tricks or hacks. Usually, all you need is to do the SEO basics really well really consistently.
- SEO is a long-term game. SEO results usually don’t appear immediately, although there are exceptions—for example, when you fix some serious issue. In general, think in months instead of days.
- SEO is more than just installing an SEO plugin. SEO plugins are useful tools. But the mere fact that you set one up does not mean your website is suddenly “SEO-friendly.”
- You're never “done” with SEO. Search engine optimization is a continuous process. Even if you rank No. 1 for all your keywords, you always need to keep improving. The competition never sleeps.
- Knowing your audience is key. The more you understand your target audience (customers, readers, subscribers), the easier it is to create an effective SEO strategy.
- SEO is just one part of the puzzle. No amount of optimization will help you if you neglect to work on the core of your business—your product or service.
Get Started With SEO
Now that you know what SEO is, it’s time to take action.
Execute on the tips we mentioned earlier, and you’ll be on your way to higher rankings. And one step ahead of your competitors.
Start by signing up for a free Semrush account (no credit card needed).
You’ll be able to:
- Do keyword research (up to 10 searches per day)
- Analyze competitors (up to 10 domains per day)
- Track your keyword rankings (up to 10 keywords)
- Run a free site audit (crawl up to 100 URLs)
- Get ideas to improve your on-page SEO (up to one campaign)
And tons more.

SEO FAQs
Finally, here are the answers to some common questions about SEO.
What Is the Role of SEO in Digital Marketing?
The prime objective of SEO is improving the visibility of a website in search engines. As such, it is a crucial part of every digital marketing strategy.
SEO creates great synergy with PPC advertising and overlaps with other areas of marketing, such as content marketing and social media marketing.
Can I Do SEO Myself?
If you’ve ever wondered whether you can DIY SEO without the help of a professional or an agency, the answer is definitely yes. All you need is a willingness to learn new things and a website where you can apply your knowledge.
How Do I Start Learning SEO?
This guide is a good stepping stone for your SEO learning journey. But if you want to dive deeper and/or prefer video content, you’ll love Semrush Academy.
Find dozens of 100% free online courses taught by top industry experts, such as Eric Enge, Brian Dean, and Nathan Gotch.
Do I Need an SEO Tool?
Your SEO actions must be based on accurate data. If you run a website that makes you money, having a complete SEO toolset that will cover all your SEO needs is a necessity. And it will pay for itself quickly.