
What Is Keyword Research?
Keyword research is the process of finding and analyzing what relevant audiences search for in search engines like Google. So you can create content that’s more likely to rank highly in search results.
It’s a crucial part of any search engine optimization (SEO) strategy. And a helpful step to take whenever you’re planning new content.
For example, a pet retailer might conduct keyword research with Semrush’s Keyword Magic Tool. And find that:
- Thousands of people per month search “how much food should i feed my dog”
- Ranking for “royal canin dog food” is harder than ranking for “royal canin cat food”
- Most people searching “best python books” want books about coding—not snakes
This kind of information can help you spend business resources more effectively. And ultimately get more organic traffic (unpaid visits from search engines).
Why Is Keyword Research Important for SEO?
Keyword research is important for SEO because it tells you what relevant audiences are looking for and helps you prioritize ranking opportunities.
By creating content that satisfies target users’ needs, you can earn organic rankings in search results. Just like the ones below. And get more valuable traffic to your site.
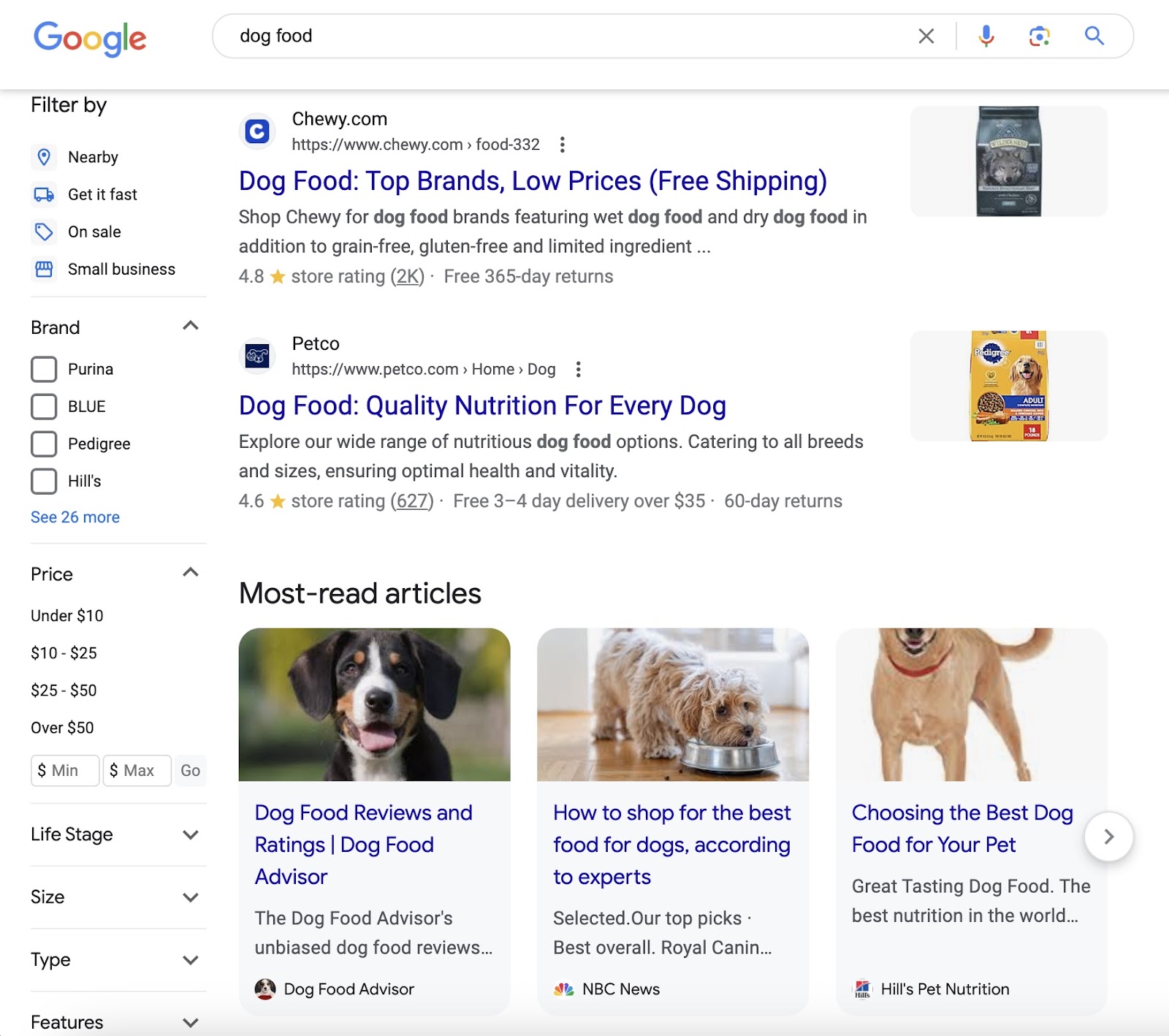
Plus, using keywords on your page can help it rank higher in search engine results pages (SERPs).
Google says content relevance is one of the most important factors when ranking search results. Adding, “The most basic signal that information is relevant is when content contains the same keywords as [the] search query.”
This means it’s helpful to know the exact wording that searchers use.
How to Find Keywords
In this section, you’ll learn how to find SEO keywords that are relevant to your site.
After that, we’ll explain how to analyze and prioritize the keywords you find.
Check Your Existing Rankings
If you have a website, it might already appear for some relevant keywords. Meaning you have existing rankings to build upon.
One of the quickest ways to find out is with Semrush’s Organic Research tool.
Enter your domain, choose your target location, and click “Search.”

Then, go to the “Positions” report.
The table shows keywords you rank for and the highest position you rank in (as of the date at the top.)

If you see an icon in the “Position” column, it means your site appears in a non-standard search result known as a SERP feature.
For example, the crown icon means that you own the featured snippet (the instant answer that typically appears at the top of the SERP).
Like this:

Later, we’ll explain how to identify the best opportunities to improve your rankings.
For now, let’s learn how to find relevant keywords you aren’t ranking for yet.
Search a Keyword Database
The most common way to conduct keyword research is to search a keyword database.
Semrush’s keyword database is the biggest on the market—it contains over 25.5 billion keywords. And you can easily search it with the Keyword Magic Tool.
Just enter a seed keyword (a term to base your search around).
Then, choose your target location and click “Search.”
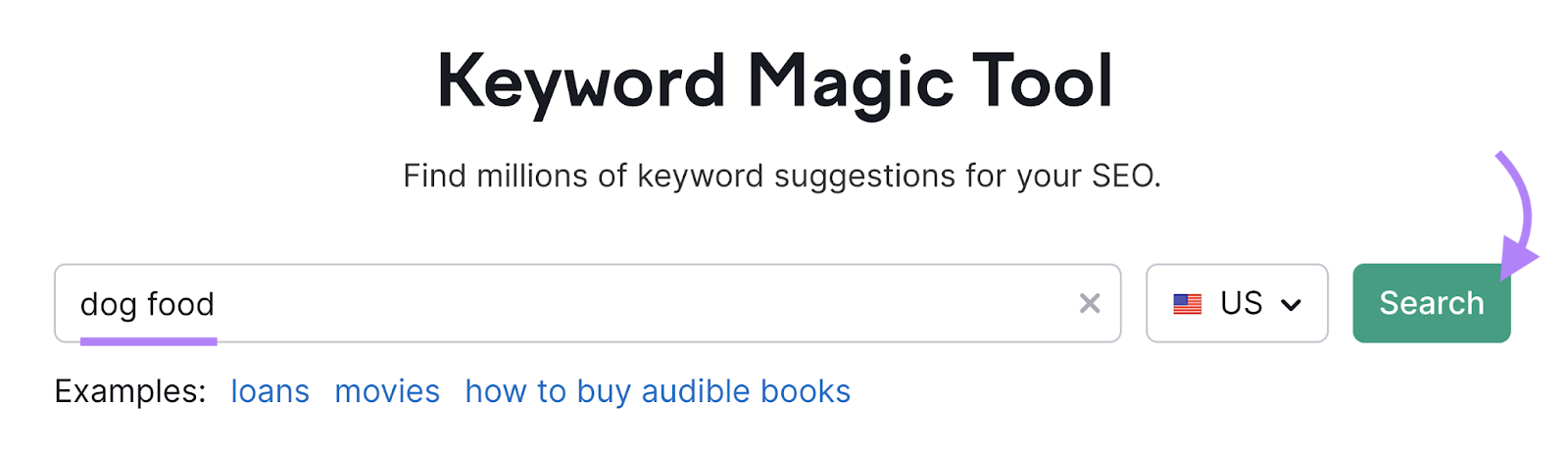
You can view five types of results:
- All Keywords: Broad match, phrase match, exact match, and related keywords
- Broad Match: Keywords that contain any variation of your seed term with the words in any order
- Phrase Match: Keywords that contain your exact seed term with the words in any order
- Exact Match: Keywords that contain your exact seed term with the words in the specified order
- Related: Keywords that generate similar search engine results to your seed keyword
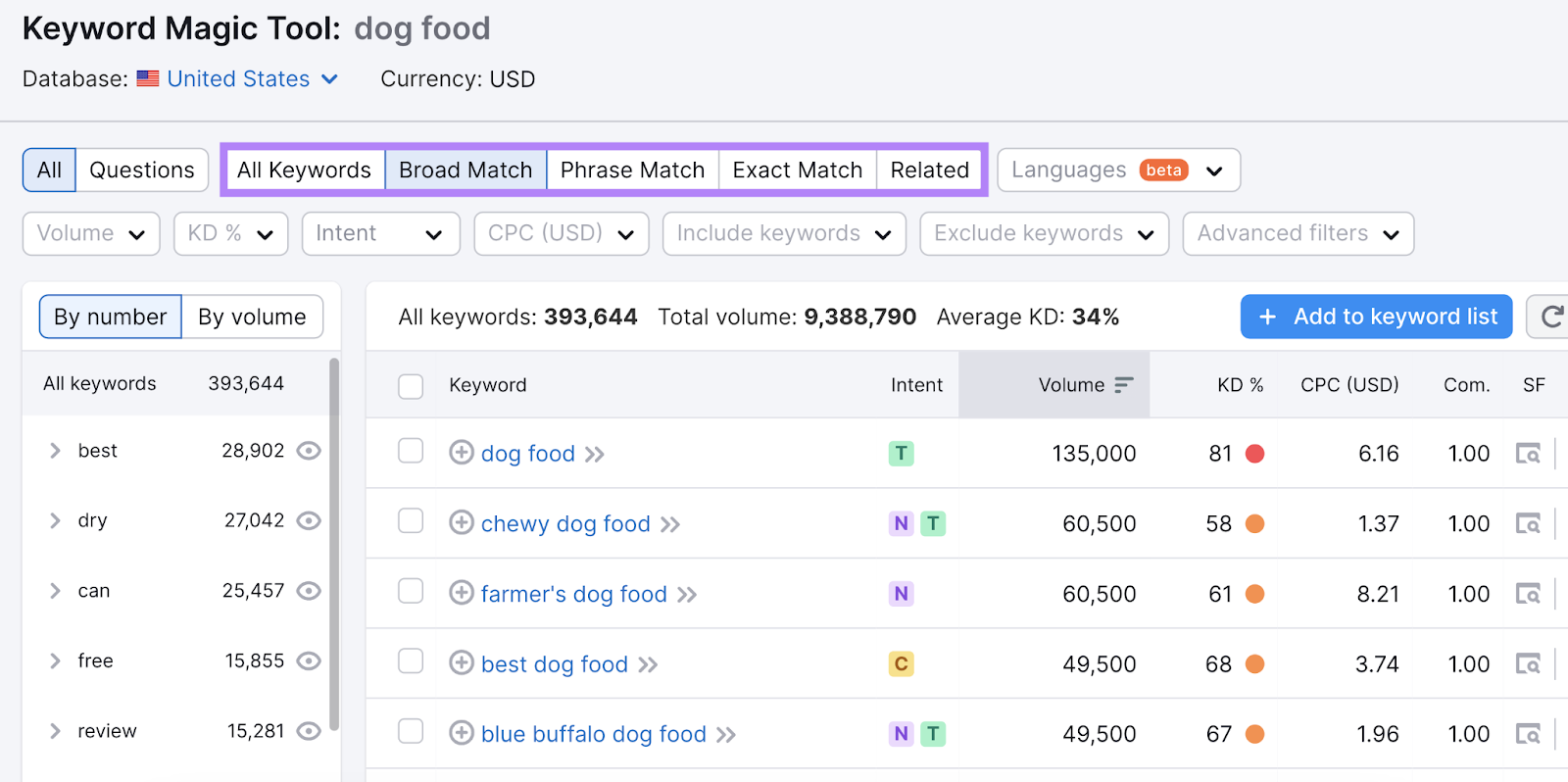
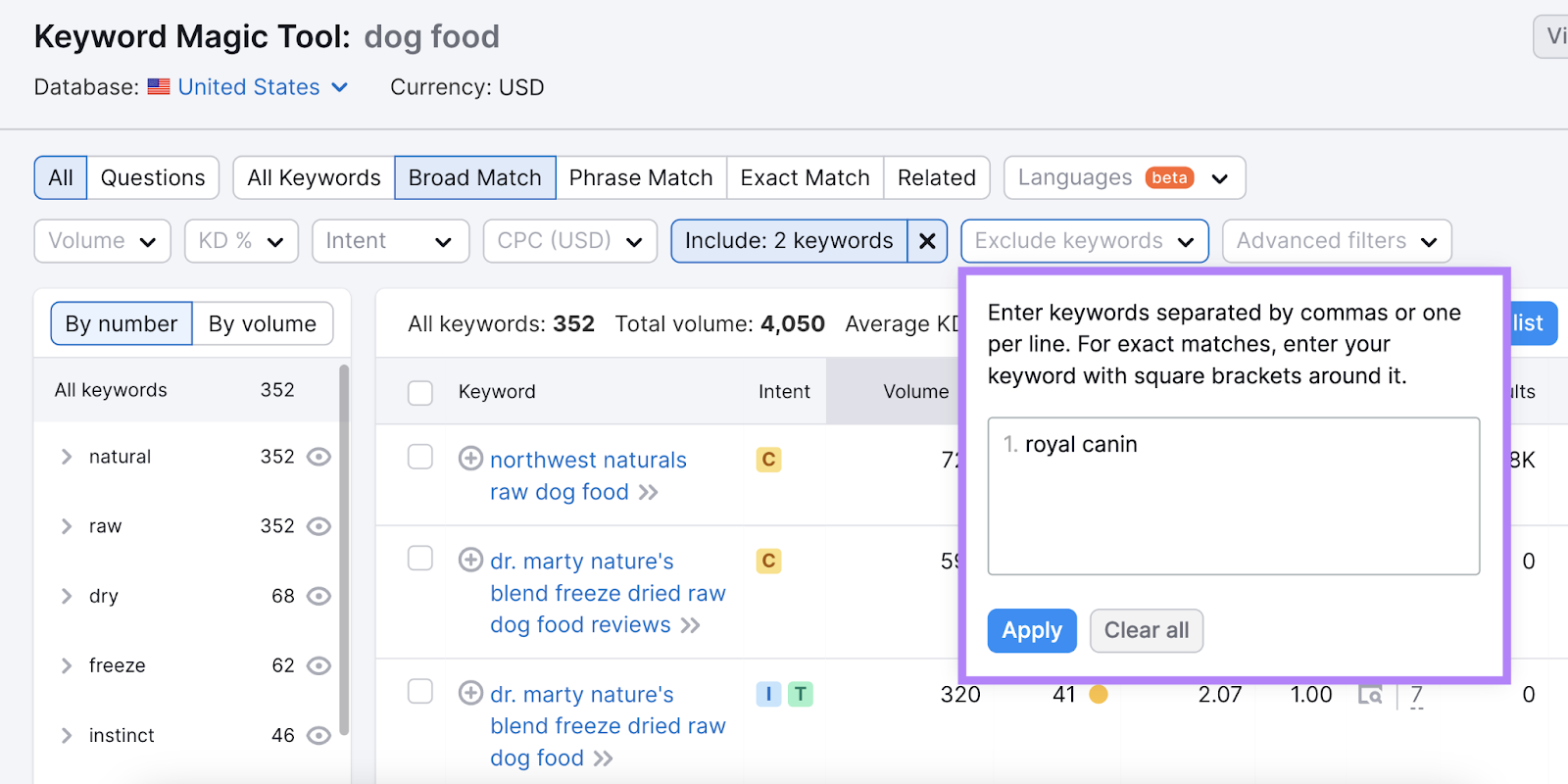
To filter your results further, you can include or exclude particular terms.
For example, our pet retailer might focus on keywords that include “raw” or “natural.”
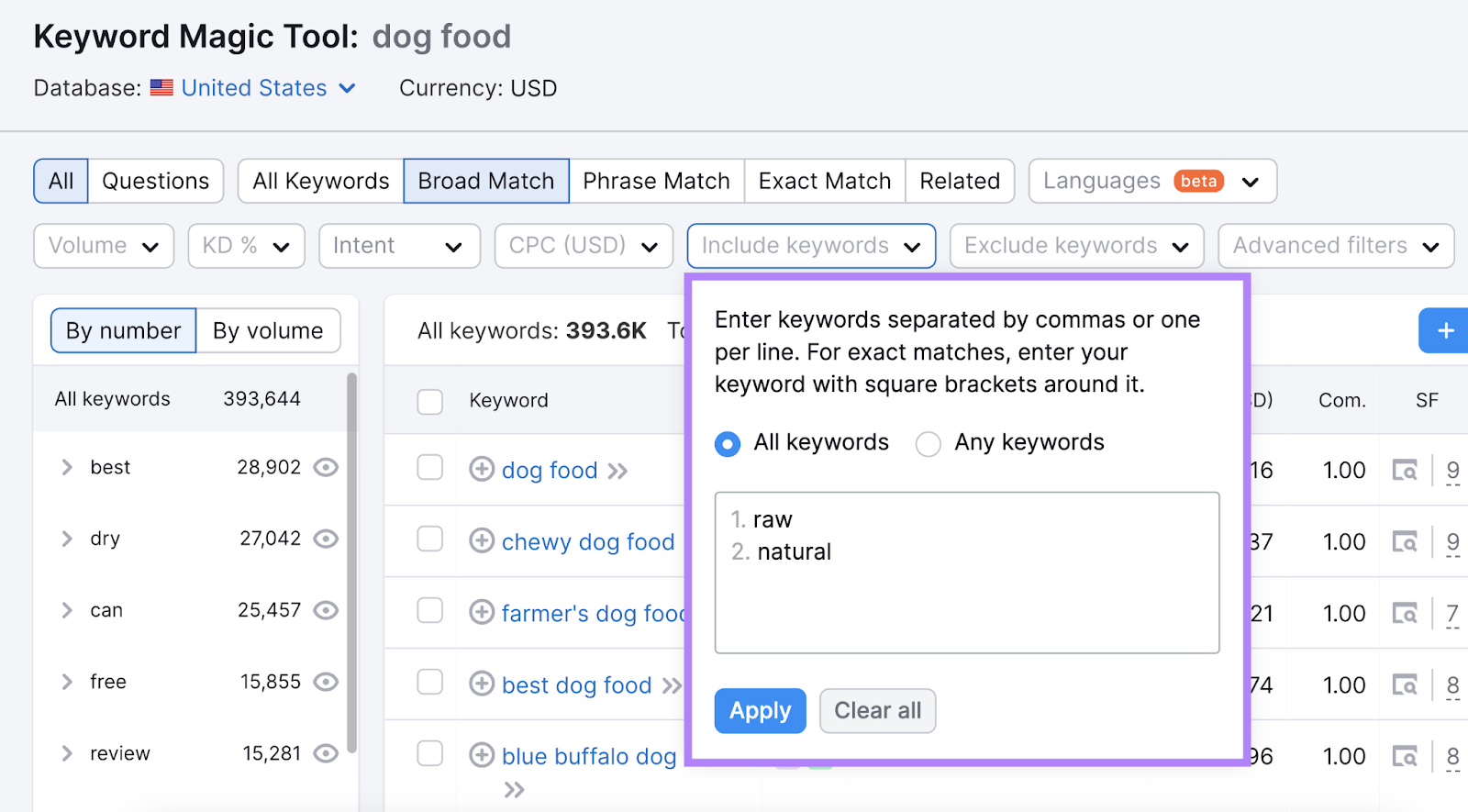
And hide brand names they don’t stock (like “royal canin”).
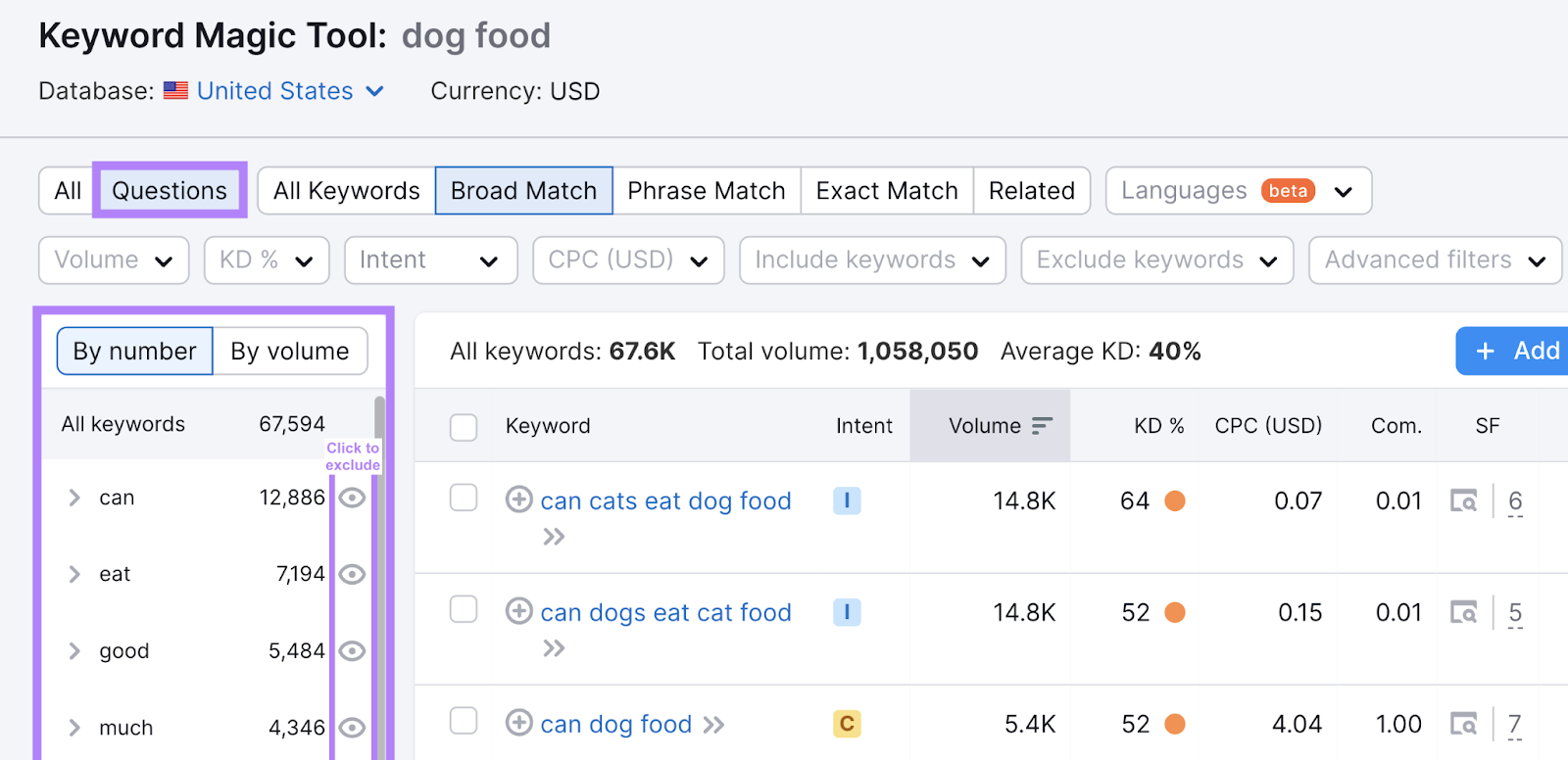
If you need inspiration, the list in the left-hand column shows the most common keyword modifiers. And you can filter them in or out in one click.
There’s also a dedicated filter for question keywords.
Later, we’ll explain how to make use of all the keyword metrics you can see.
Conduct a Keyword Gap Analysis
A keyword gap analysis reveals keywords that competitors rank for but you don’t. It’s an effective way to find relevant keywords you’re missing out on.
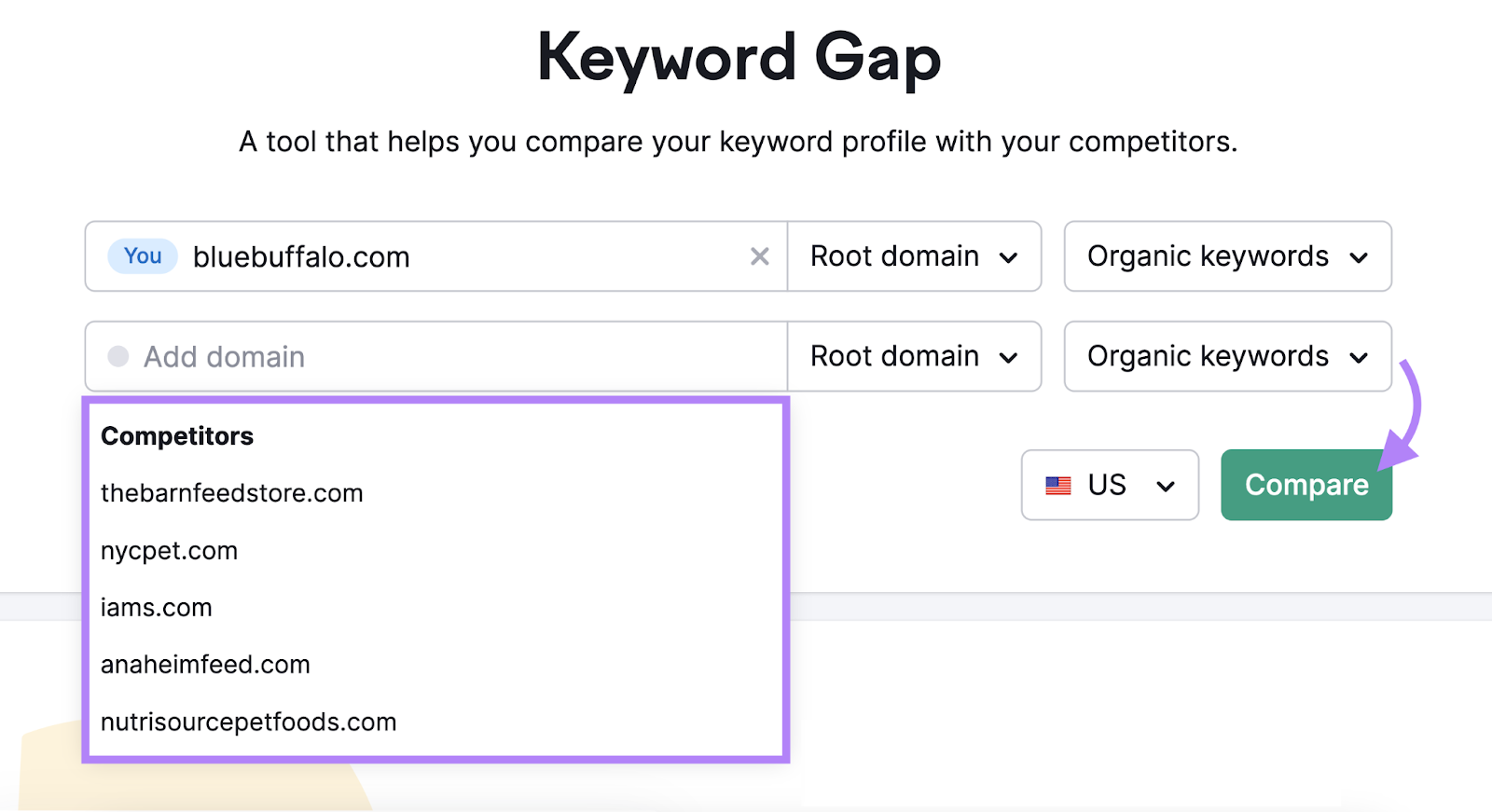
And you can try it for free with Semrush’s Keyword Gap tool.
Just enter your domain and up to four competitors’ domains. (You can type in your competitors manually or pick the organic competitors the tool suggests.)
Then, choose your location and click “Compare.”
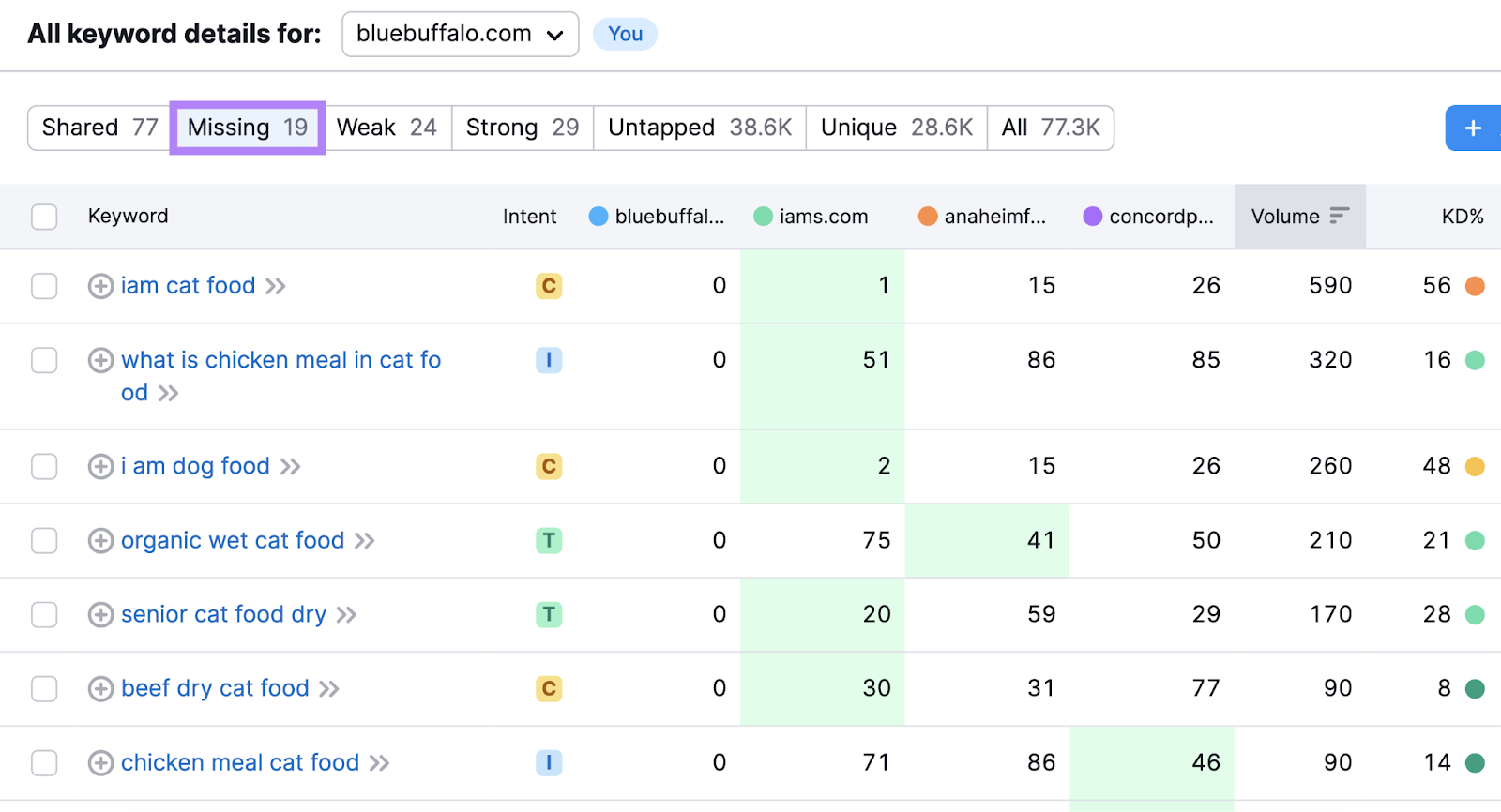
Scroll down to the keywords table and select “Missing.”
This shows you keywords that all competitors rank for but you don’t. So, they should be highly relevant.
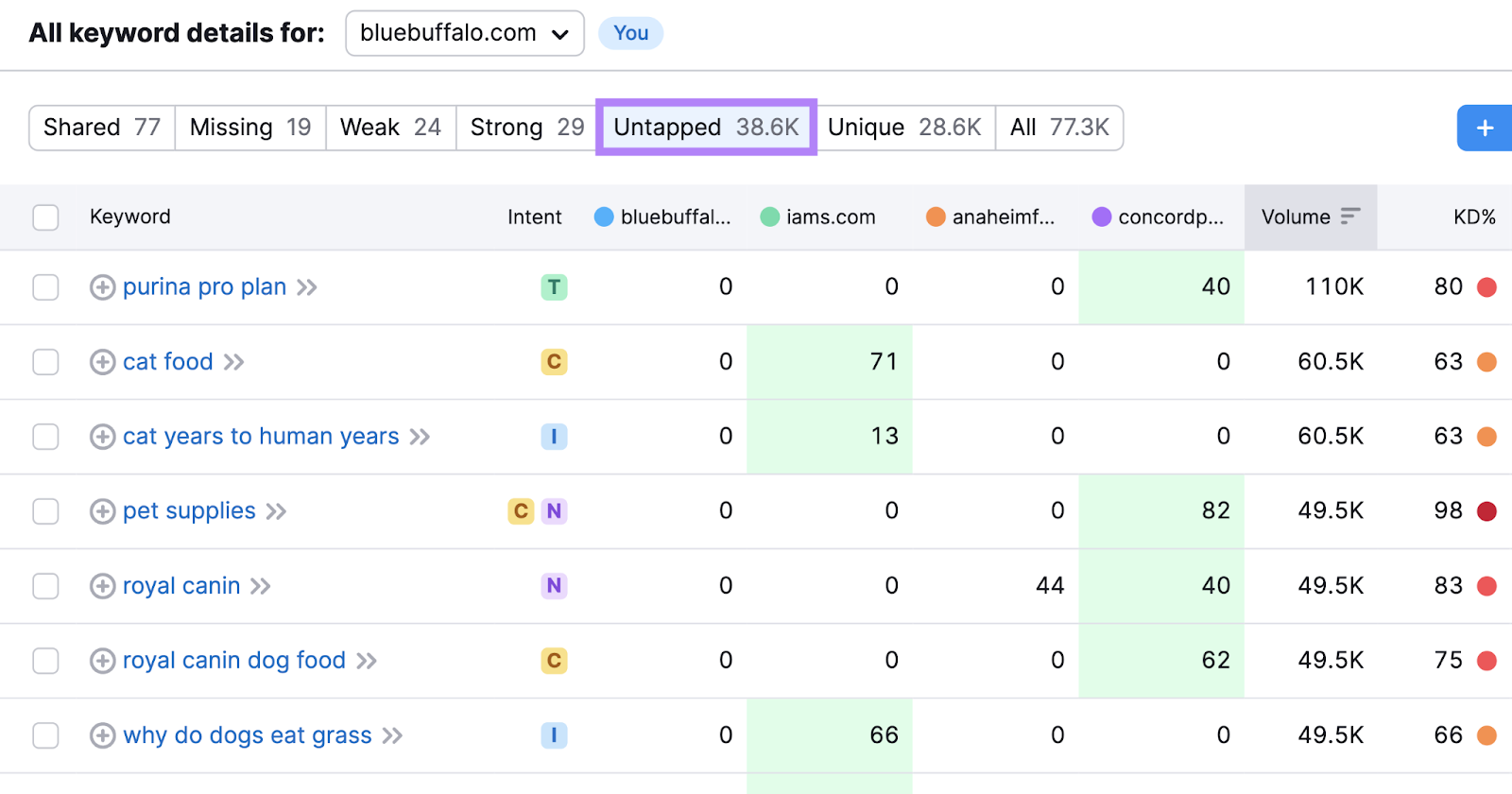
To see keywords that at least one competitor ranks for but you don’t, go to “Untapped.”
These might be less relevant, but you could find some hidden gems.
Look at Search Suggestions in Search Engines
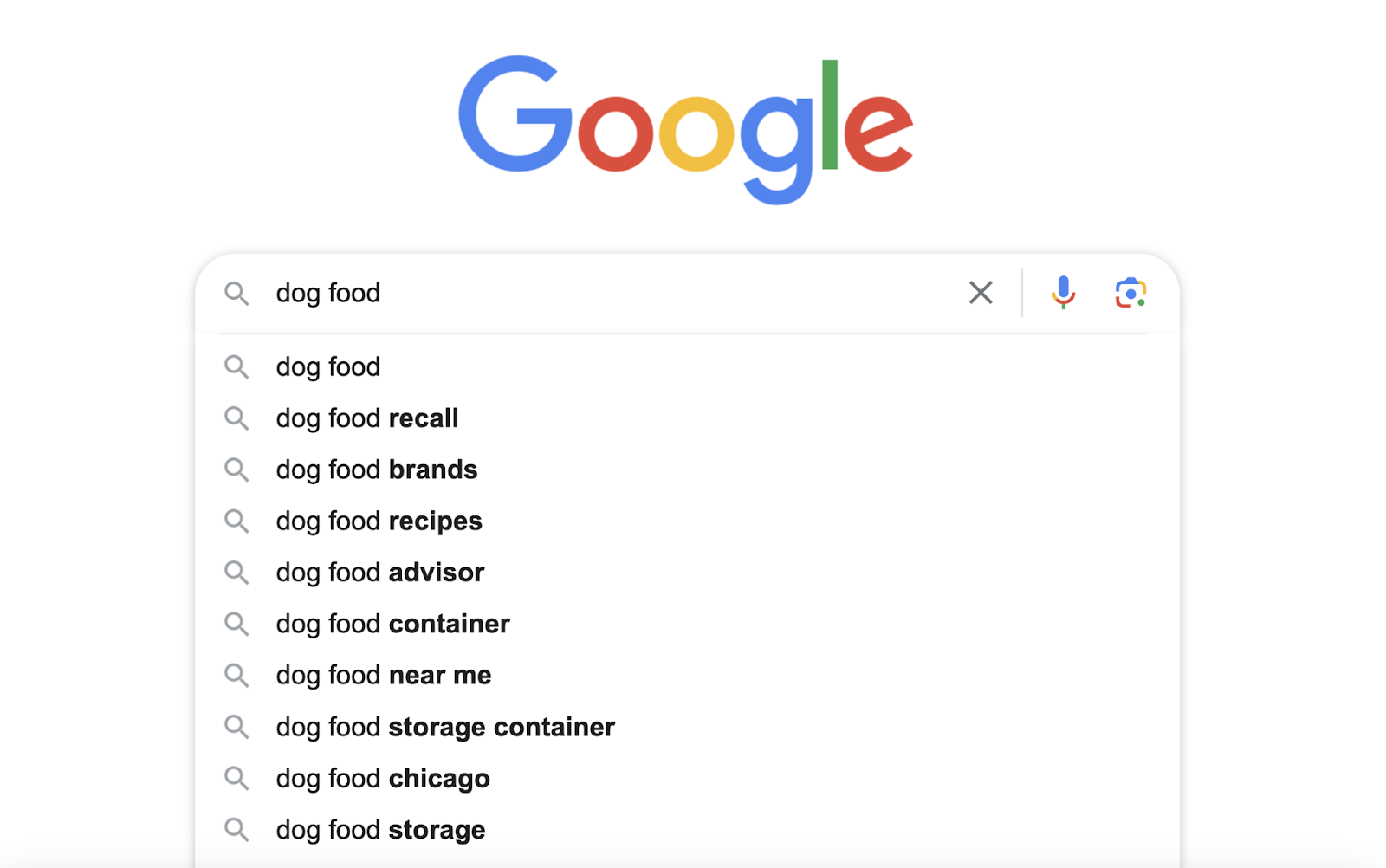
You can conduct basic keyword research by looking at search suggestions in search engines.
For example, Google offers autocomplete predictions when you start typing. And you can use this as a way to identify popular queries in your niche.
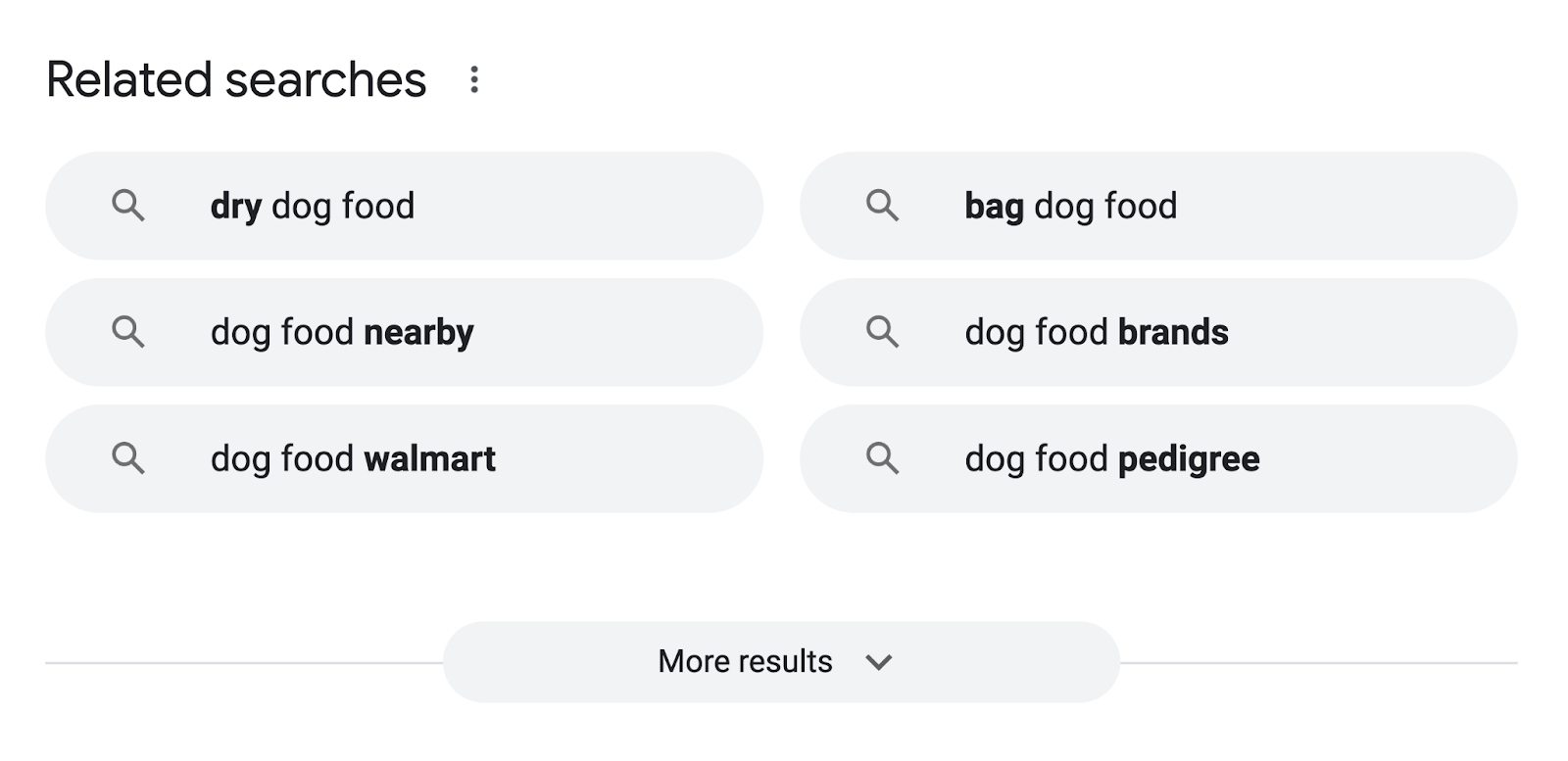
You can also note down keywords that appear in the “Related searches” sections of relevant SERPs.
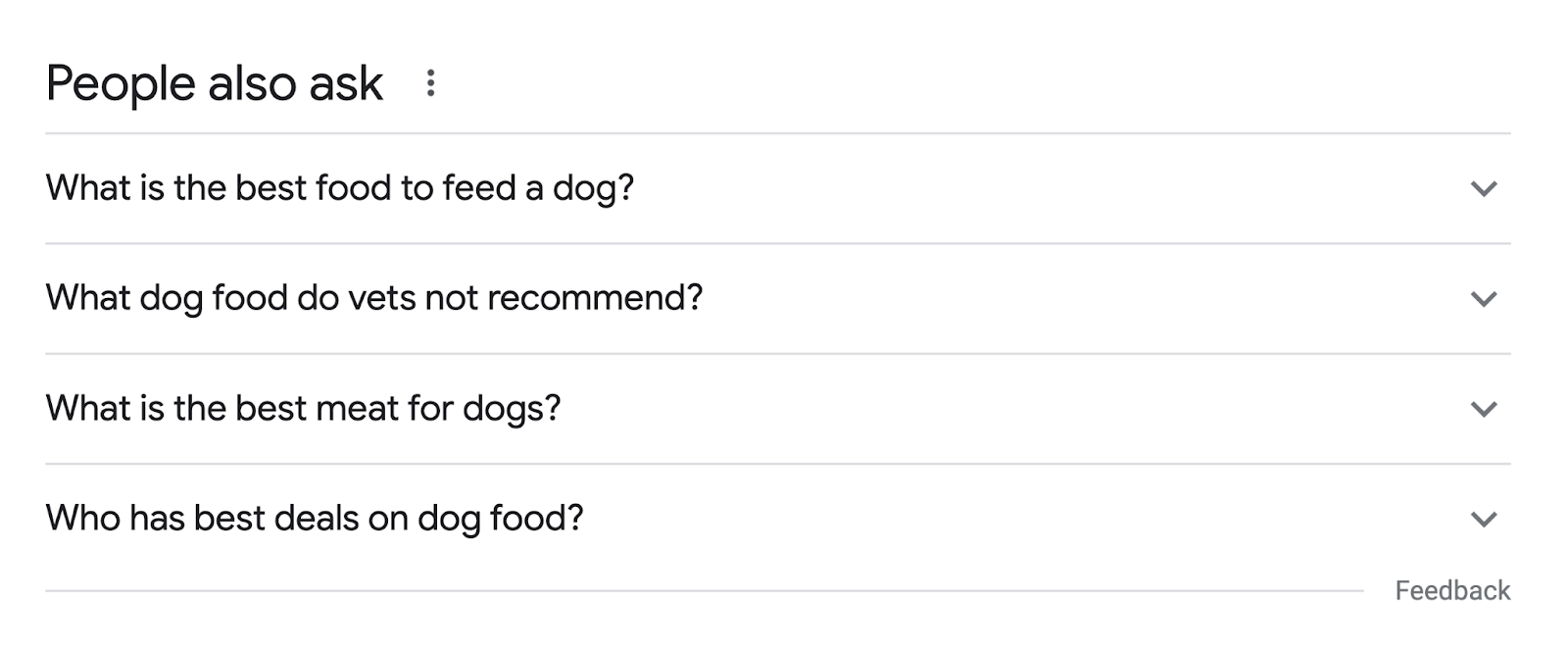
And question keywords that appear in “People also ask” boxes.
Like this one:
But this method is time-consuming and provides a limited number of results.
Plus, if you want to collect useful metrics, you’ll need to import your keywords to another tool.
That’s why we recommend sticking with dedicated keyword research tools.
How to Choose Keywords
Your initial keyword research can yield thousands of keyword ideas. And not all of them will be relevant or important to your brand.
To choose the best keywords for SEO, you need to:
- Gather useful metrics from SEO keyword research tools
- Analyze the SERPs to see what results are shown
For the best results, we recommend working through this checklist:
Understand Search Intent
Search intent is the reason behind a user’s search.
To understand what a keyword can do for your business—and how to rank for it—you need to know the usual search intent behind it.
For example, people who search “pedigree small dog” typically want to purchase Pedigree-branded food for small dog breeds. So, the top-ranking results are relevant product pages.
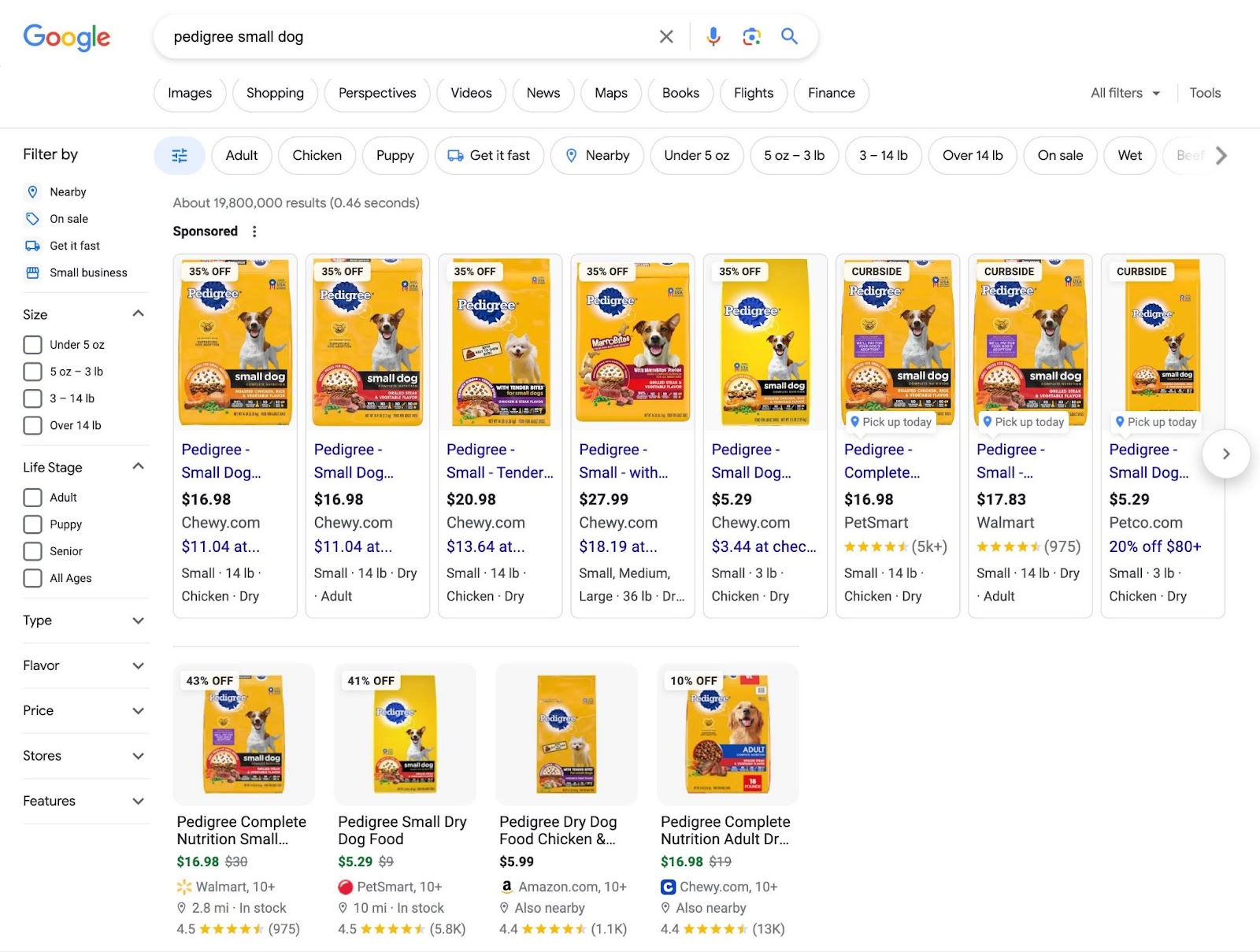
When you research keywords in Semrush, you can see what type(s) of intent a keyword has.
There are four categories:
- Navigational: The user is looking for a specific page (e.g., “pedigree foundation”)
- Informational: The user is looking for general information on a topic (e.g., “can dogs eat spicy food”
- Commercial: The user is researching their options before making the final decision on which product to buy (e.g., “best dry dog food”)
- Transactional: The user is looking for a specific product or brand, with the intention to make a purchase (e.g., “pedigree puppy food”)
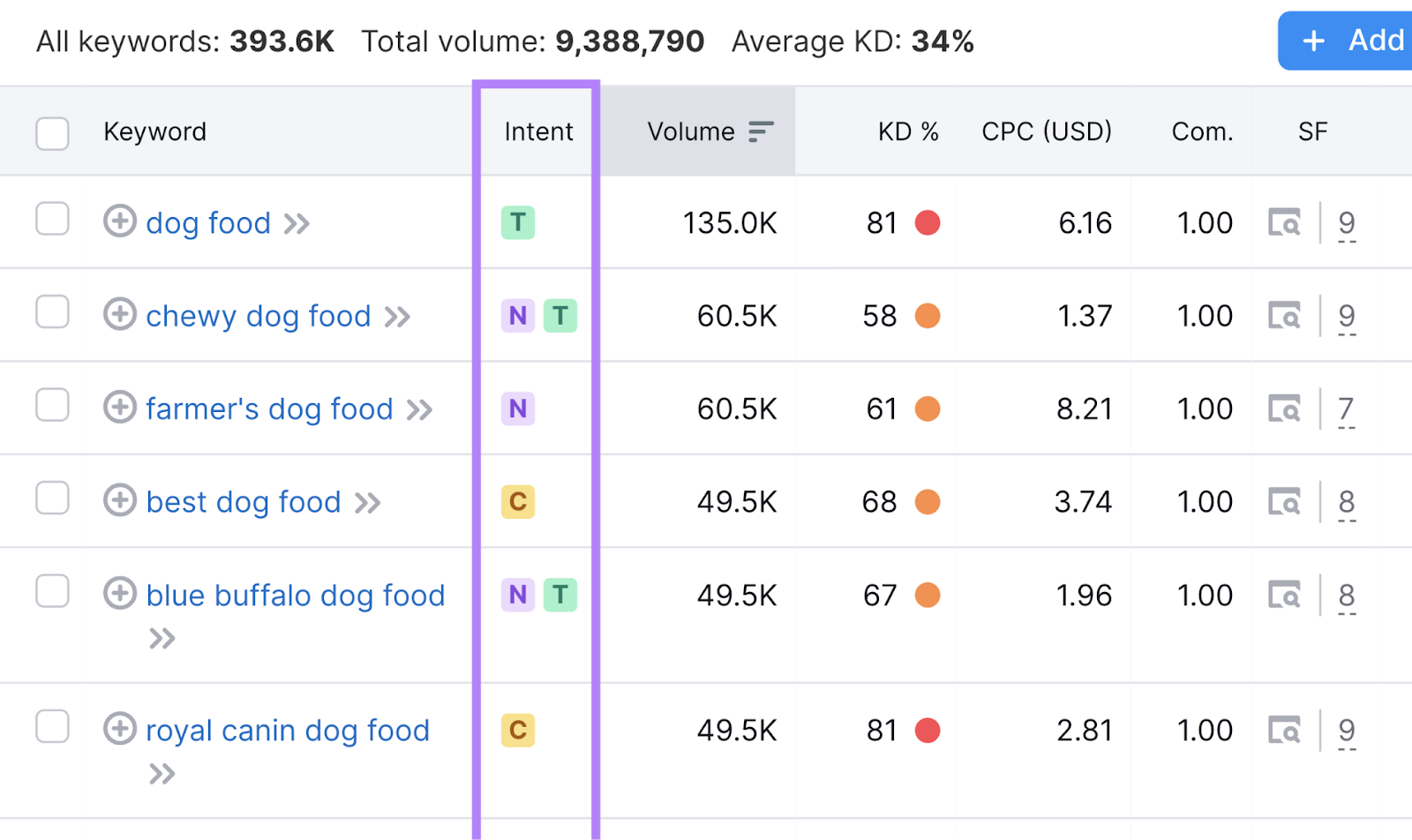
You can get further insights into search intent by looking at the top-ranking results.
Just click the “View SERP” button or icon. Here’s what the icon looks like in the Keyword Magic Tool:
For example, our pet retailer might think to target “best dog food” on their dog food category page.
But all the top results are roundups from industry publications:
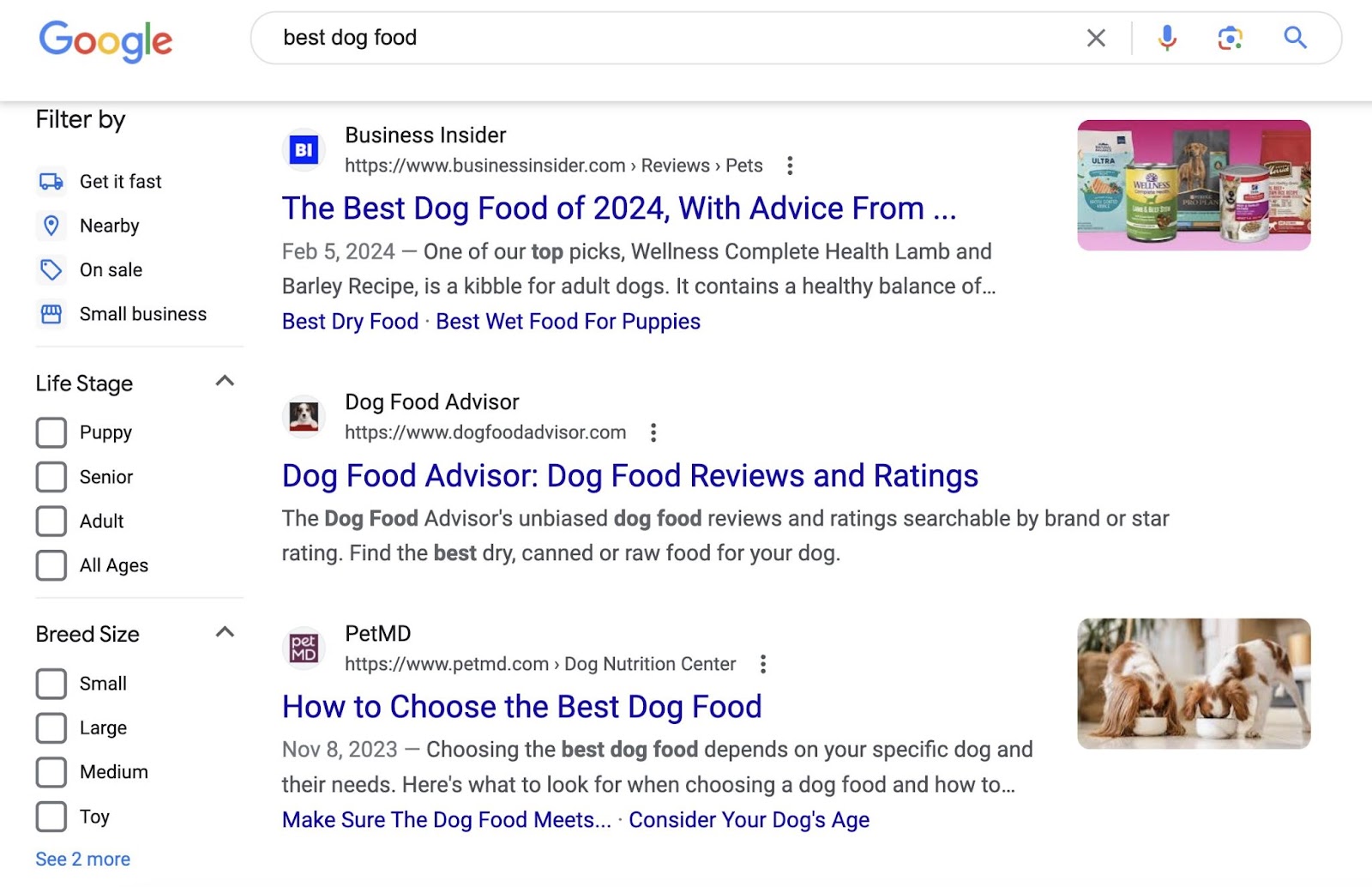
This suggests that it will be difficult for the pet retailer to secure a high ranking—especially with a product category page.
So, they might be better off targeting other keywords instead.
Look at Keyword Search Volumes
Search volume tells you how many times searchers enter a particular keyword into Google per month (on average).
The higher the search volume, the more traffic you’ll potentially get if you rank well for that keyword. So, all else being equal, you should prioritize higher-volume keywords.
You’ll see volumes when doing keyword research in Semrush.
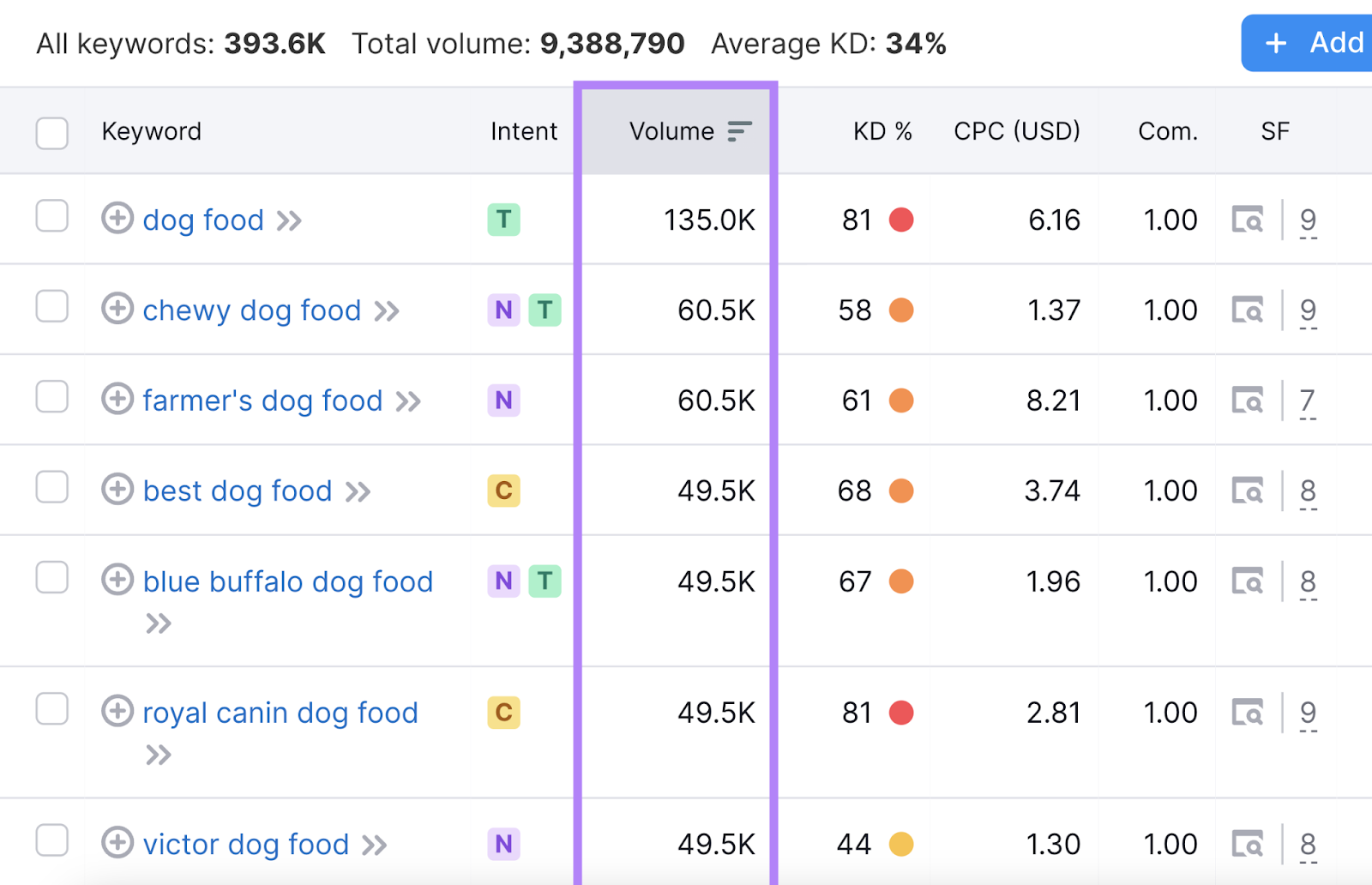
And you can filter for keywords with specific volumes (e.g., over 100 searches per month).
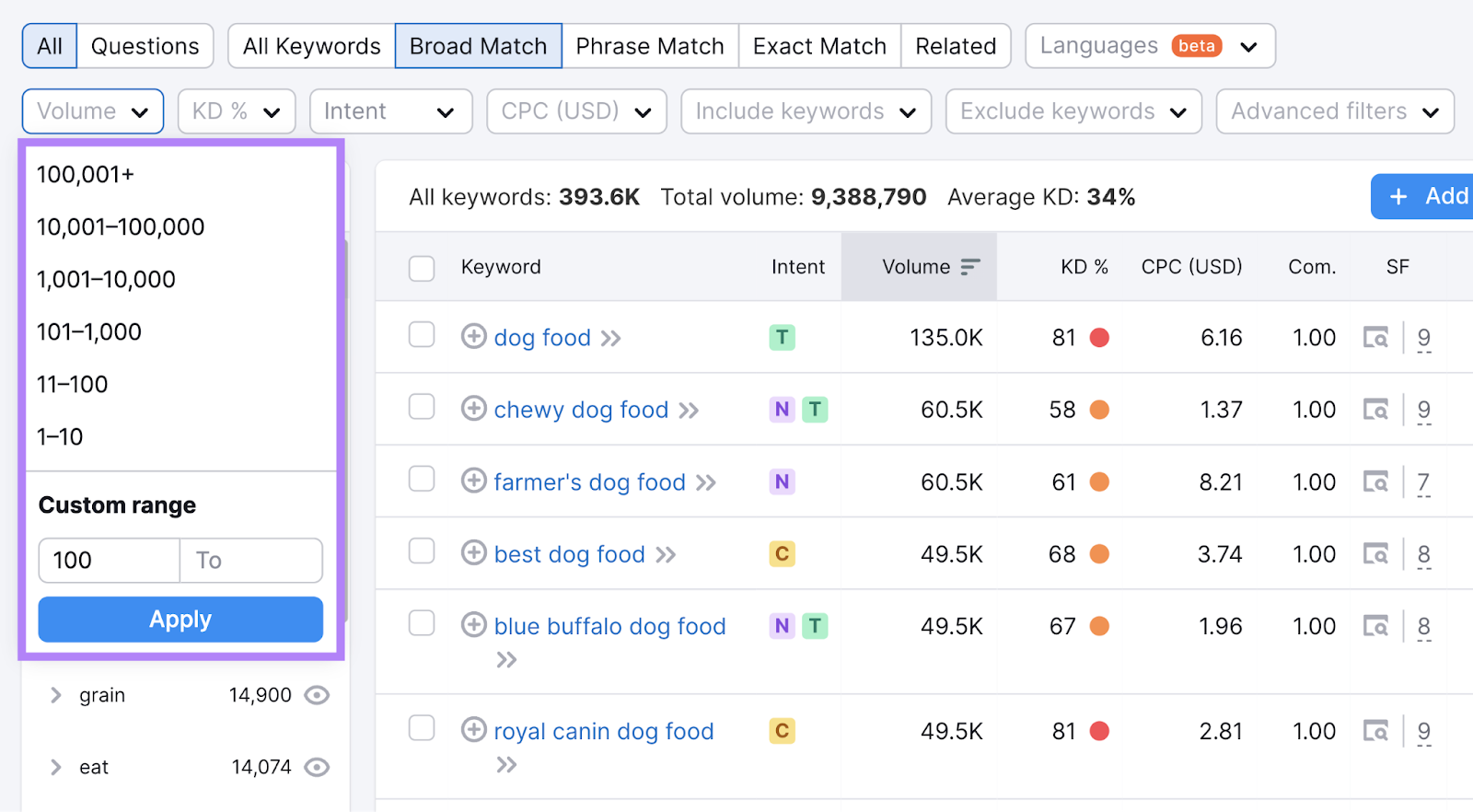
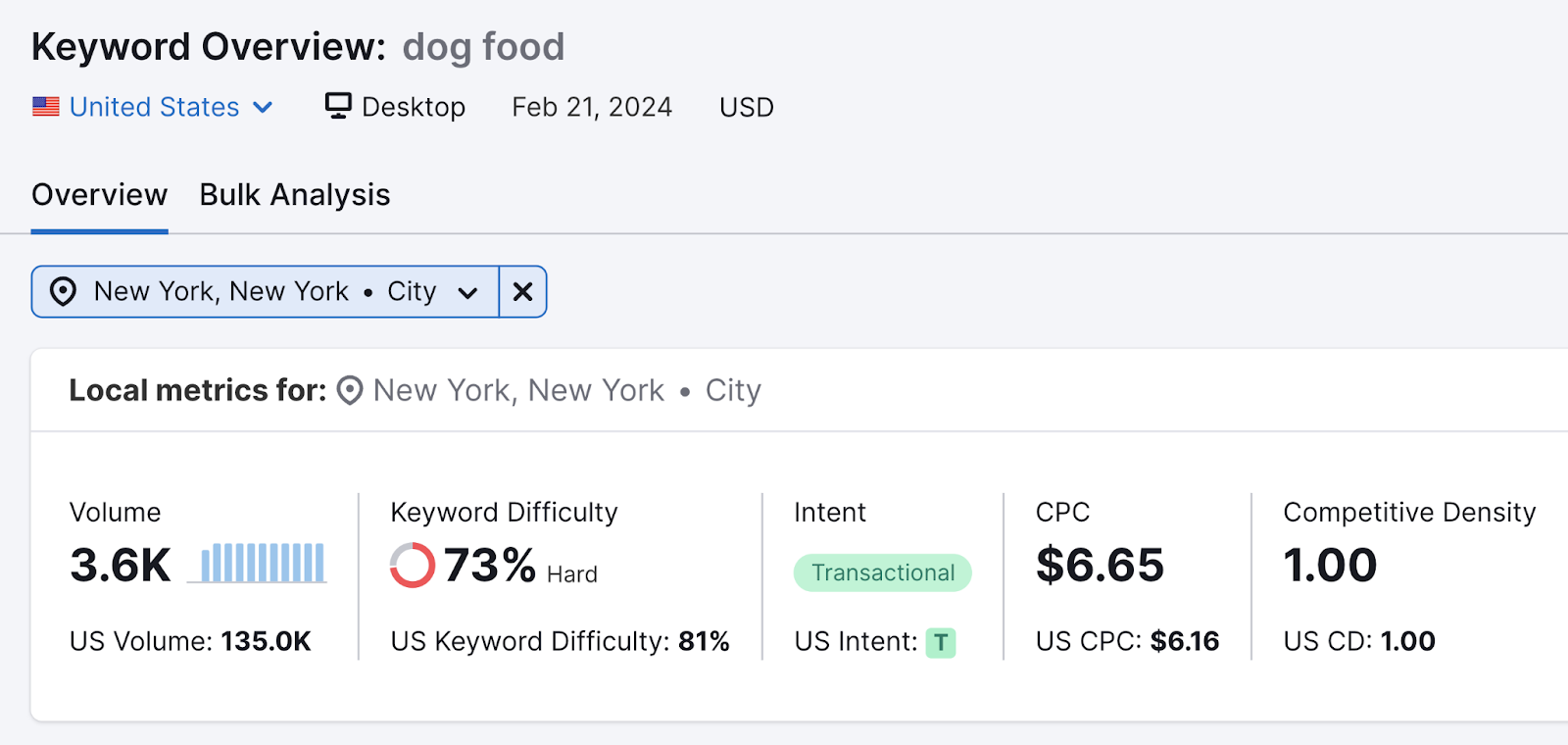
To check volumes for keywords found outside of Semrush, try entering them into the Keyword Overview tool.
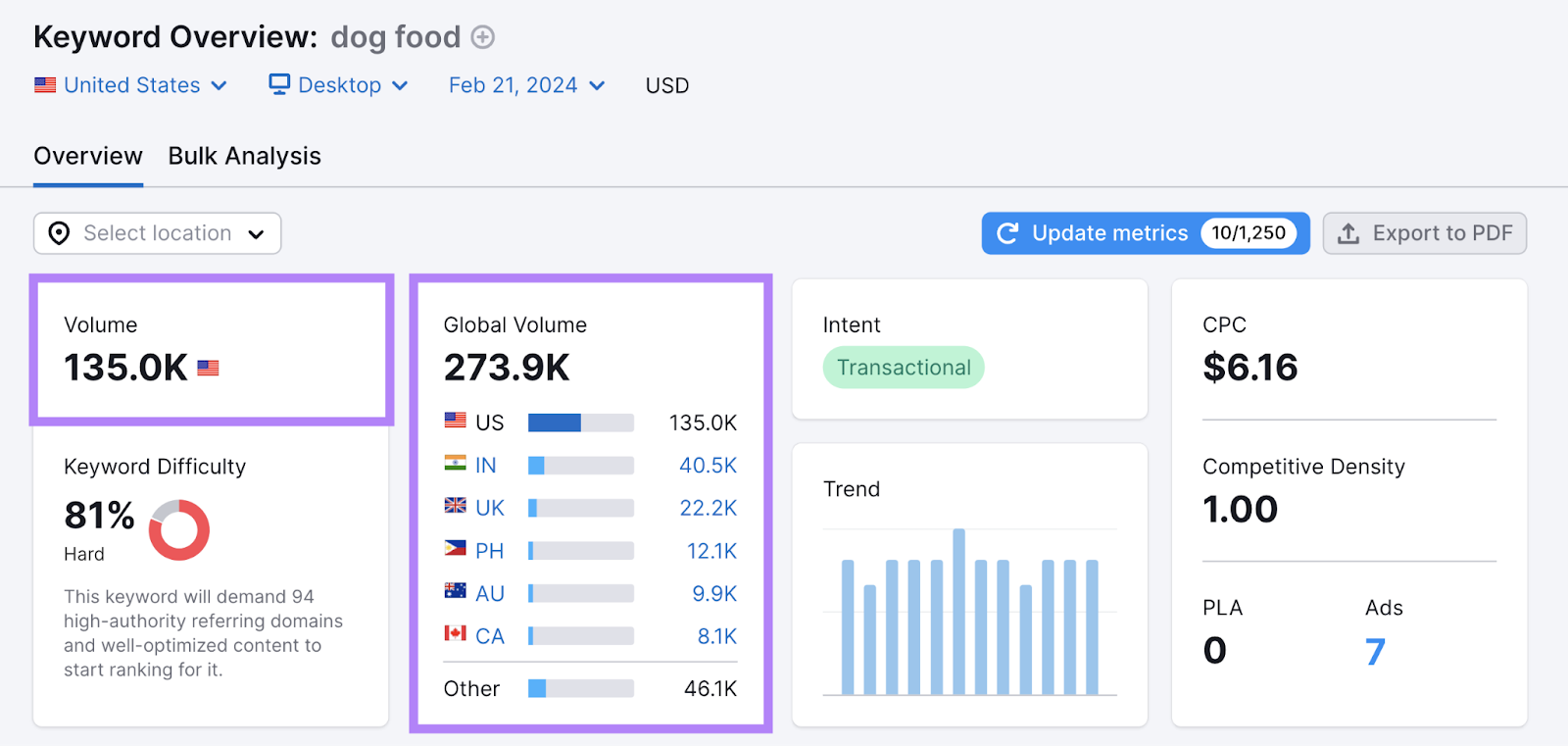
This tool even lets you check search volumes in specific regions (e.g., cities).
And compare volumes across different countries.
Consider Keyword Difficulty
Keyword difficulty (KD%) is a measure of how hard it is to rank highly in Google’s organic results. The higher the score, the harder it’ll be to earn a top ranking.
To compete for high-difficulty keywords, you’ll probably need:
- Very high-quality content
- Lots of links from reputable domains
- Topical authority on the subject matter
- Strong technical SEO (e.g., a fast, functional, and secure website)
Generally, keyword difficulty scores correlate with search volumes. Because keywords that get searched more tend to be more competitive.
More specific keywords (known as long-tail keywords) tend to have lower difficulty scores.
Here’s what keyword difficulty looks like in Keyword Magic Tool:
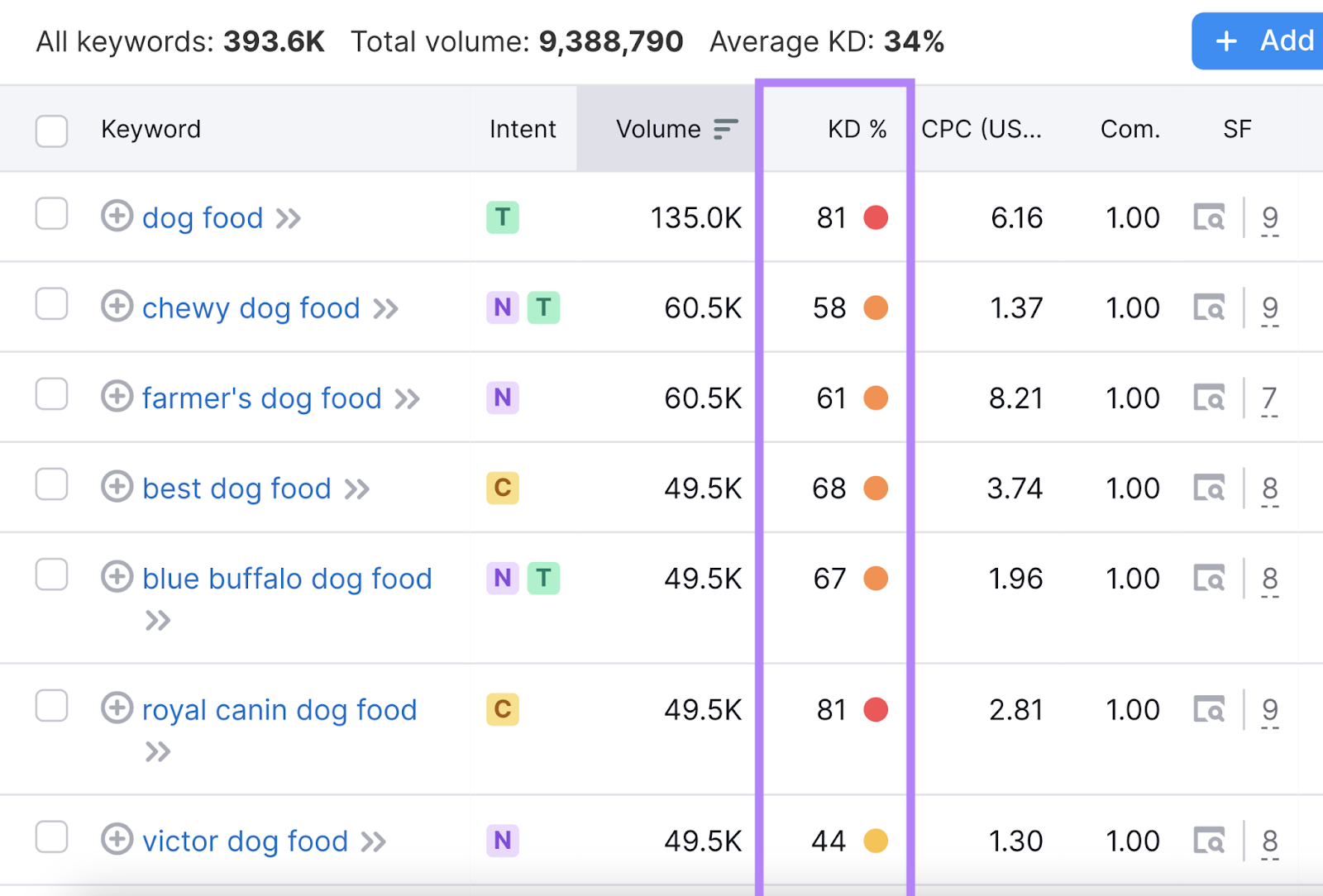
We split KD% into six categories to make analysis easier:
| KD% | Difficulty Level | Color Coding |
| 0-14 | Very easy | Dark green |
| 15-29 | Easy | Light green |
| 30-49 | Possible | Yellow |
| 50-69 | Difficult | Orange |
| 70-84 | Hard | Light red |
| 85-100 | Very hard | Dark red |
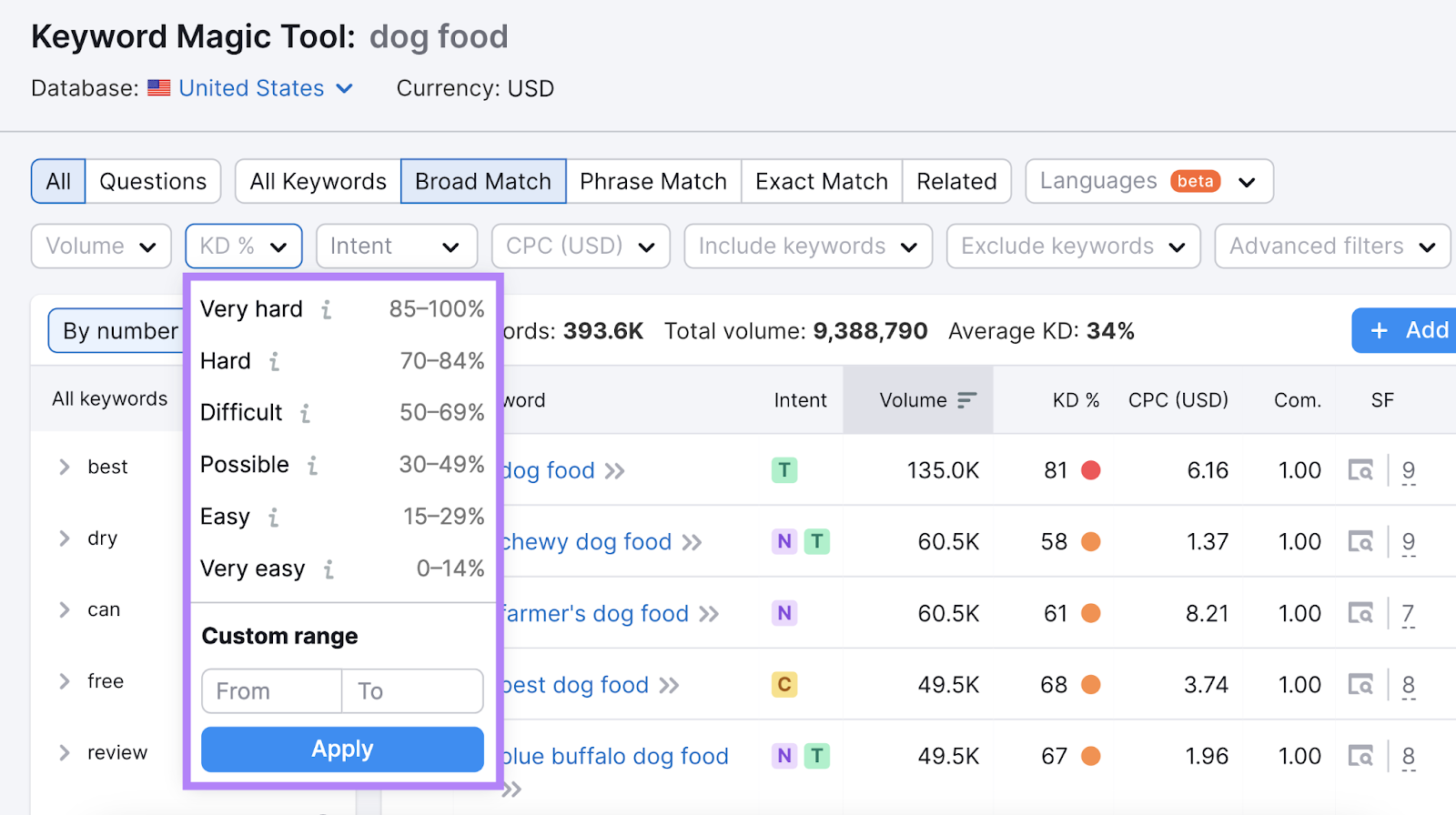
When doing keyword research for SEO, it’s a good idea to filter your results based on KD%.
For example, you might want to focus on keywords in the “Very easy” range when you’re just starting out with a new website.
Check for SERP Features
SERP features can present both an opportunity and a threat.
- Opportunity: You can rank organically for some SERP features. This can lead to more impressions and clicks, because SERP features tend to stand out and provide more information.
- Threat: Some SERP features eliminate the need for users to click on results. Or detract clicks from standard organic results.
So, their presence may affect your keyword decisions.
For example, the top organic result for “cat food” appears pretty far down the page:
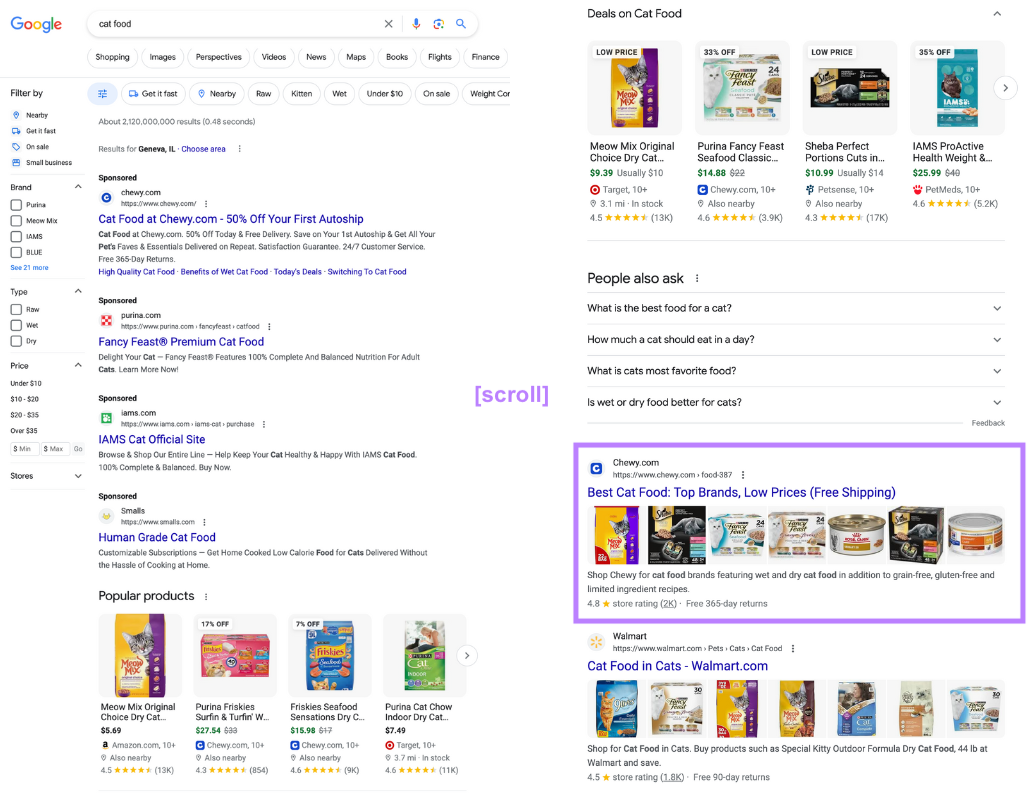
Rather than pursuing the number-one ranking for this keyword, you might be better off pursuing exposure in the popular products SERP feature.
Or targeting another keyword altogether.
When you do keyword research in Semrush, you can see how many SERP features each keyword triggers.
And hover to see exactly which ones they are.
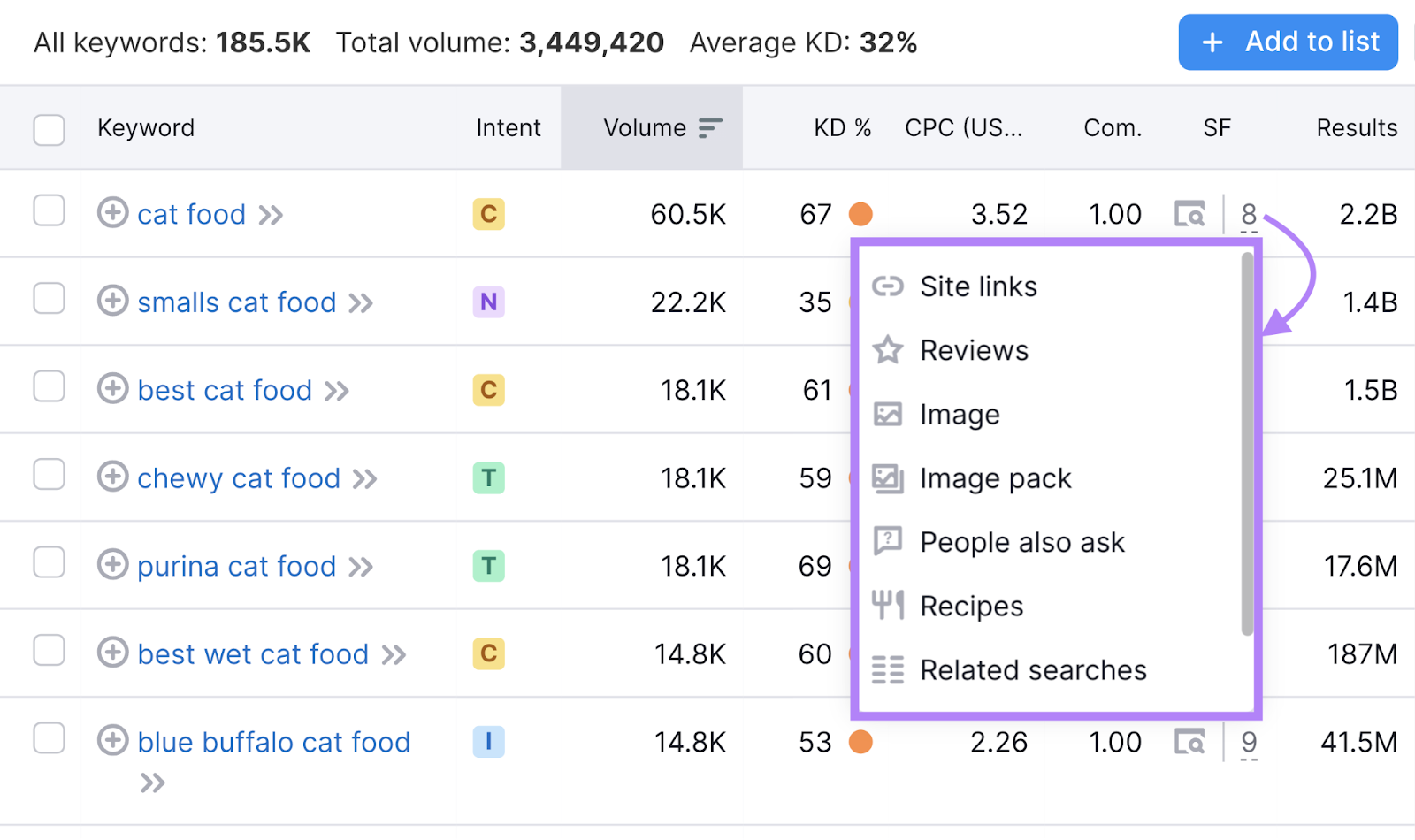
You can also click through to view the SERP for yourself. And get an idea of how much visibility each result is getting.
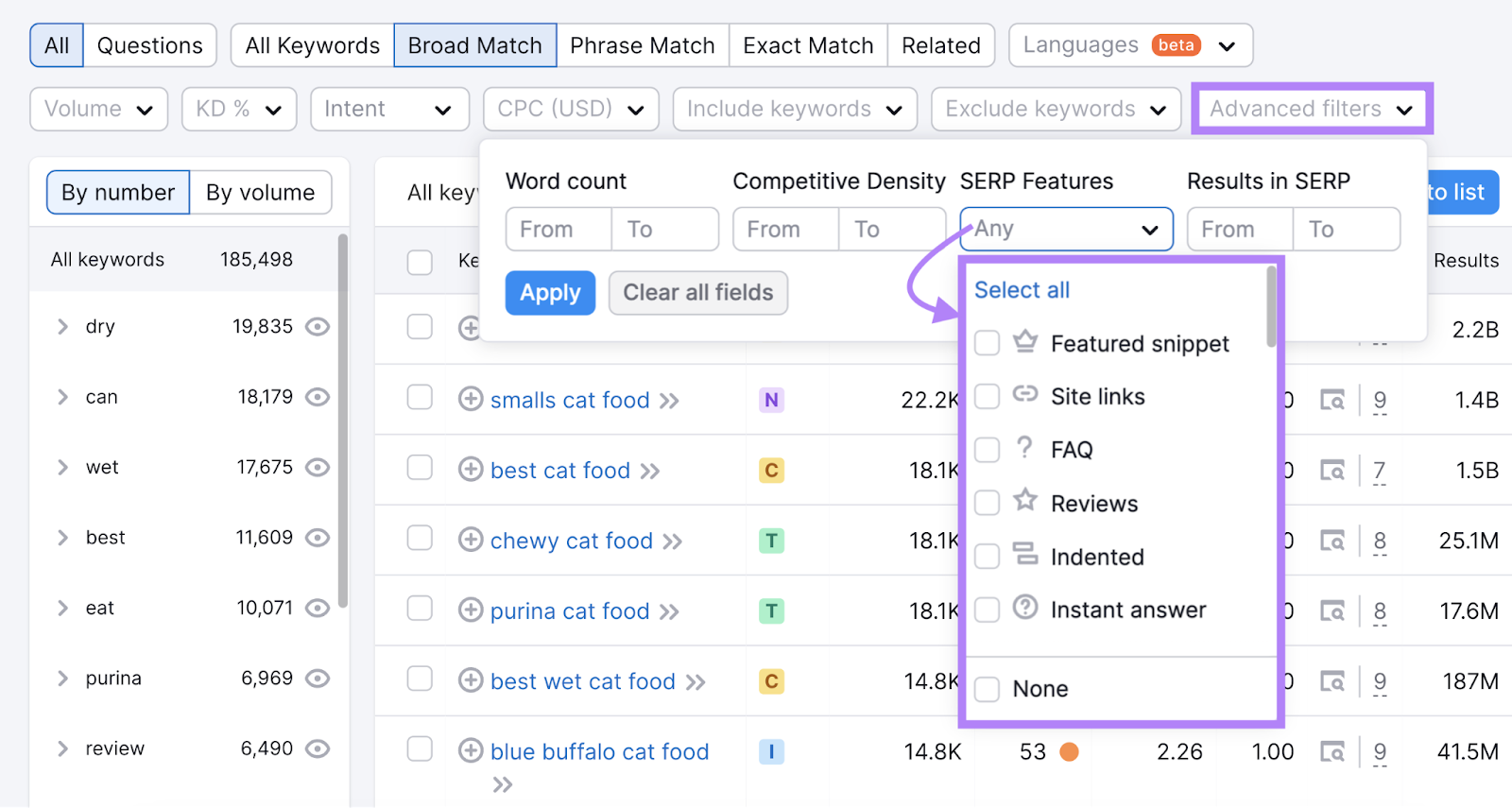
If you want to avoid (or pursue) keywords that trigger certain SERP features, use the filter option.
Like so:
Do a Cost-Benefit Analysis
Keyword analysis is ultimately about weighing the cost of getting a keyword ranking against its potential value.
To evaluate costs, you need to think about time and money. So, ask yourself:
- How long will it take to create and maintain high-ranking content?
- Do we have the ability to create the content in-house?
- Do we need to invest in content creation tools?
- Who will create the content and what could they be doing instead?
Now, let’s look at the benefits your optimized content could generate:
| Brand awareness | The amount of exposure your result gets largely depends what type of result it is, what position it’s in, and the keyword’s search volume. You may also get more visibility on desktop SERPs compared to mobile SERPs. |
| Organic traffic | The number of clicks your result gets depends on its type/position, the keyword’s search intent, and the keyword’s search volume. You can get organic traffic estimates when you analyze SERPs in Keyword Overview (and some other tools). |
| Conversions | The number of organic visits that translate into conversions (desirable actions) depends heavily on search intent. To get an idea, look at the cost per click (CPC) metric in Semrush. This tells you how much advertisers are willing to pay for a click from the SERP—the higher the amount, the more valuable the keyword is likely to be. |
| Backlinks | Links from other sites (backlinks) can drive referral traffic and benefit your SEO. The amount you can generate depends significantly on the topic and quality of your content. Which you can learn more about in our guide to link bait. |
| Topical authority | By developing high-quality content on topics relevant to your brand, you can build a strong reputation among search engines and users. This can ultimately lead to more traffic, backlinks, and conversions. |
Quantifying these benefits is tricky. But as you work on your content strategy and monitor your results, you should develop a good instinct for what works for your brand.
For detailed advice, check out our guide to SEO forecasting.
How to Target Keywords
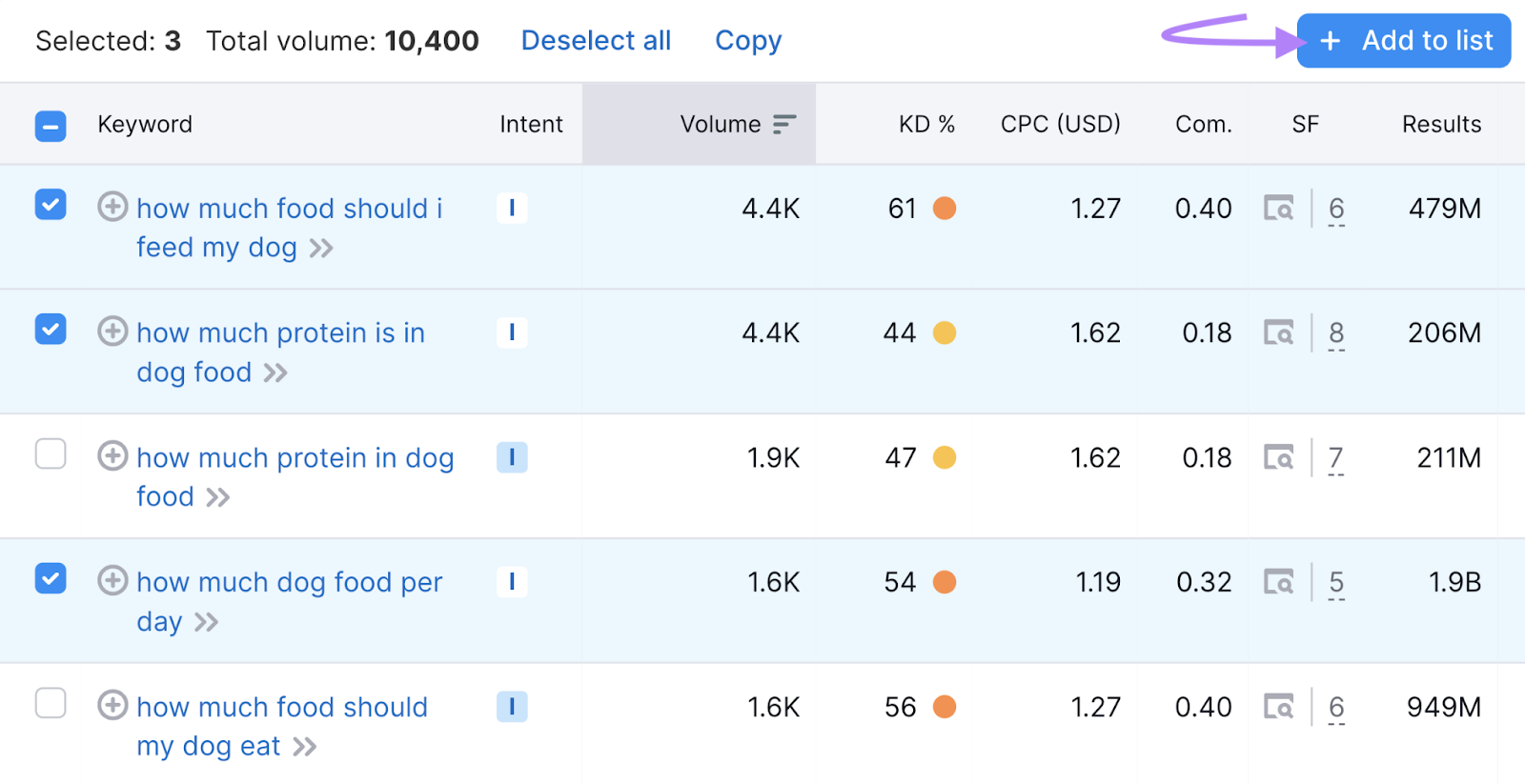
Once you’ve chosen your target keywords, make sure to record them along with any useful insights.
In Semrush, you can use the checkboxes and “+ Add to keyword list” button to save keywords in the Keyword Manager.
When you’re done with that, it’s time to develop a keyword strategy and start creating content.
Here are our top tips for success:
Create Keyword Clusters
Keyword clustering is the process of grouping keywords that share the same or very similar search intent.
You should target keywords in clusters because it:
- Helps you rank for multiple keywords with the same piece of content
- Reduces the risk of keyword cannibalization (an SEO issue that can occur when multiple pages satisfy the same search intent)
- Gives you a fuller understanding of the demand for a particular page
- Provides further insight into search intent
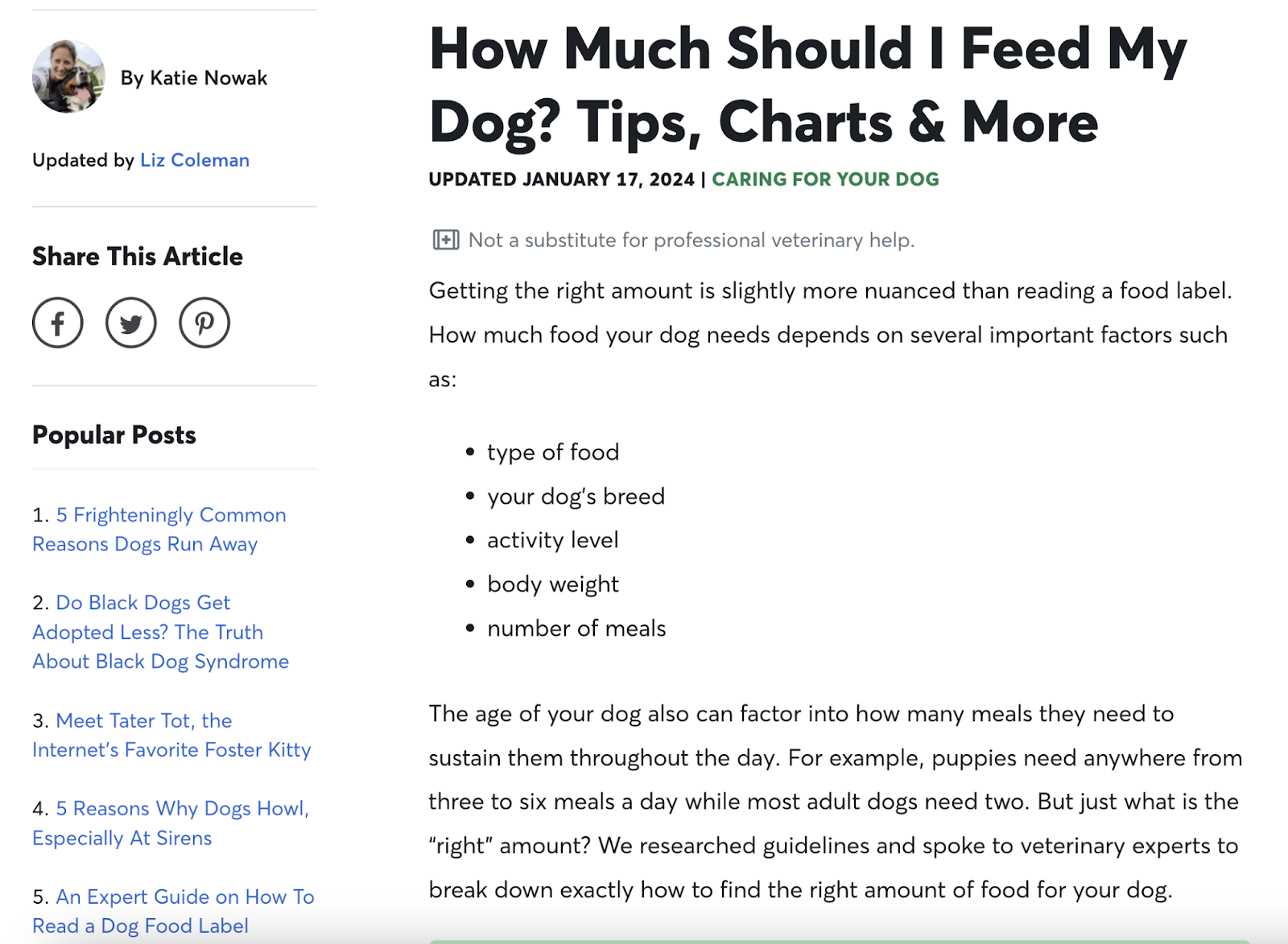
For example, Rover’s dog feeding guide targets keywords like “how much food should I feed my dog,” “how much should my puppy eat,” and “dog feeding chart.”
You can save time on keyword clustering with Semrush’s Keyword Manager.
Just open a keyword list you’ve already created. Or, click “create a regular list” and import your chosen keywords.
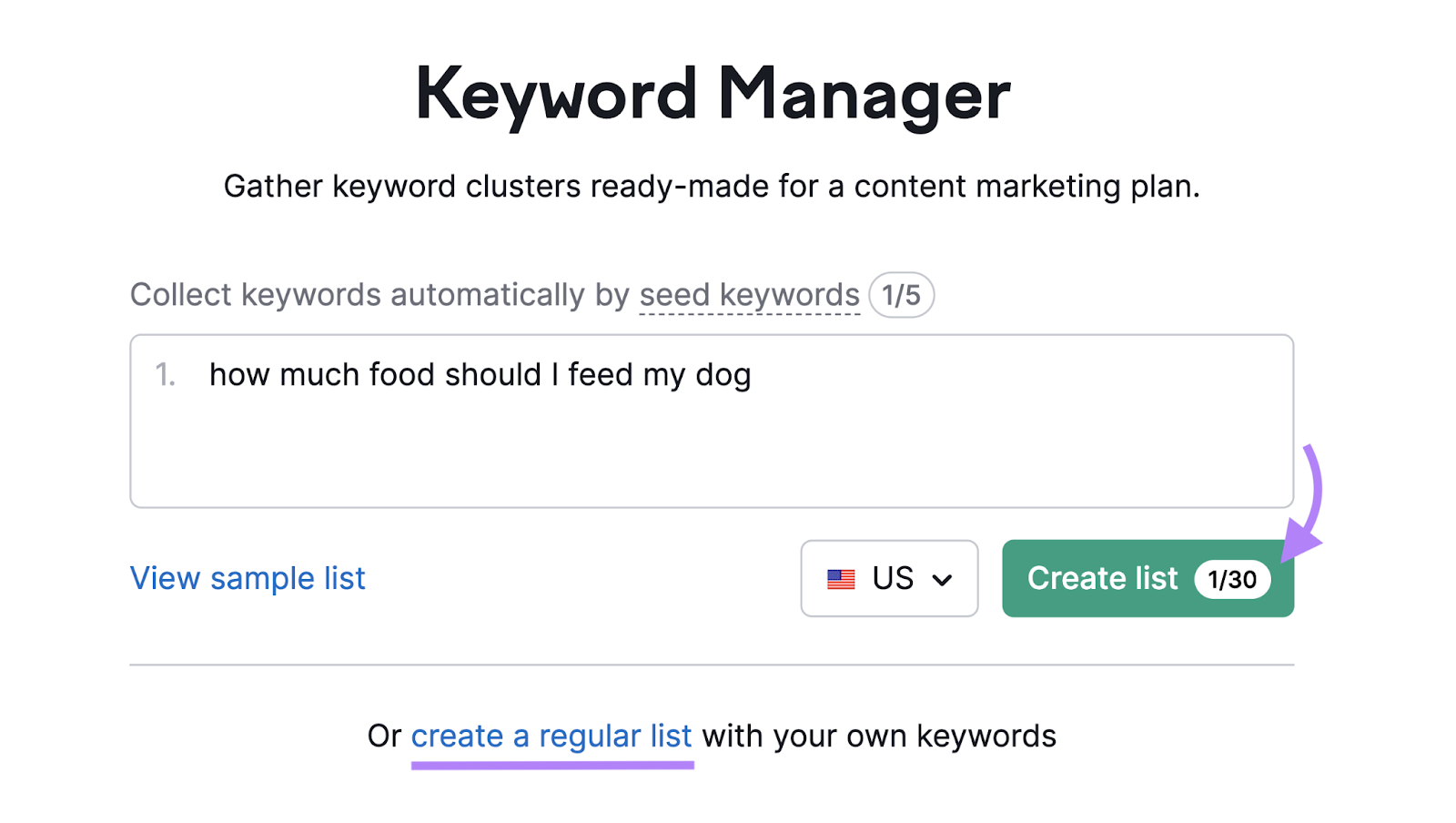
Then, click “Cluster this list.”
The tool will automatically group related keywords based on topic. And provide the following metrics:
- Intent: A breakdown of search intent types
- Keywords: The number of keywords in the cluster
- KD %: The average keyword difficulty score
- Volume: The collective keyword search volume
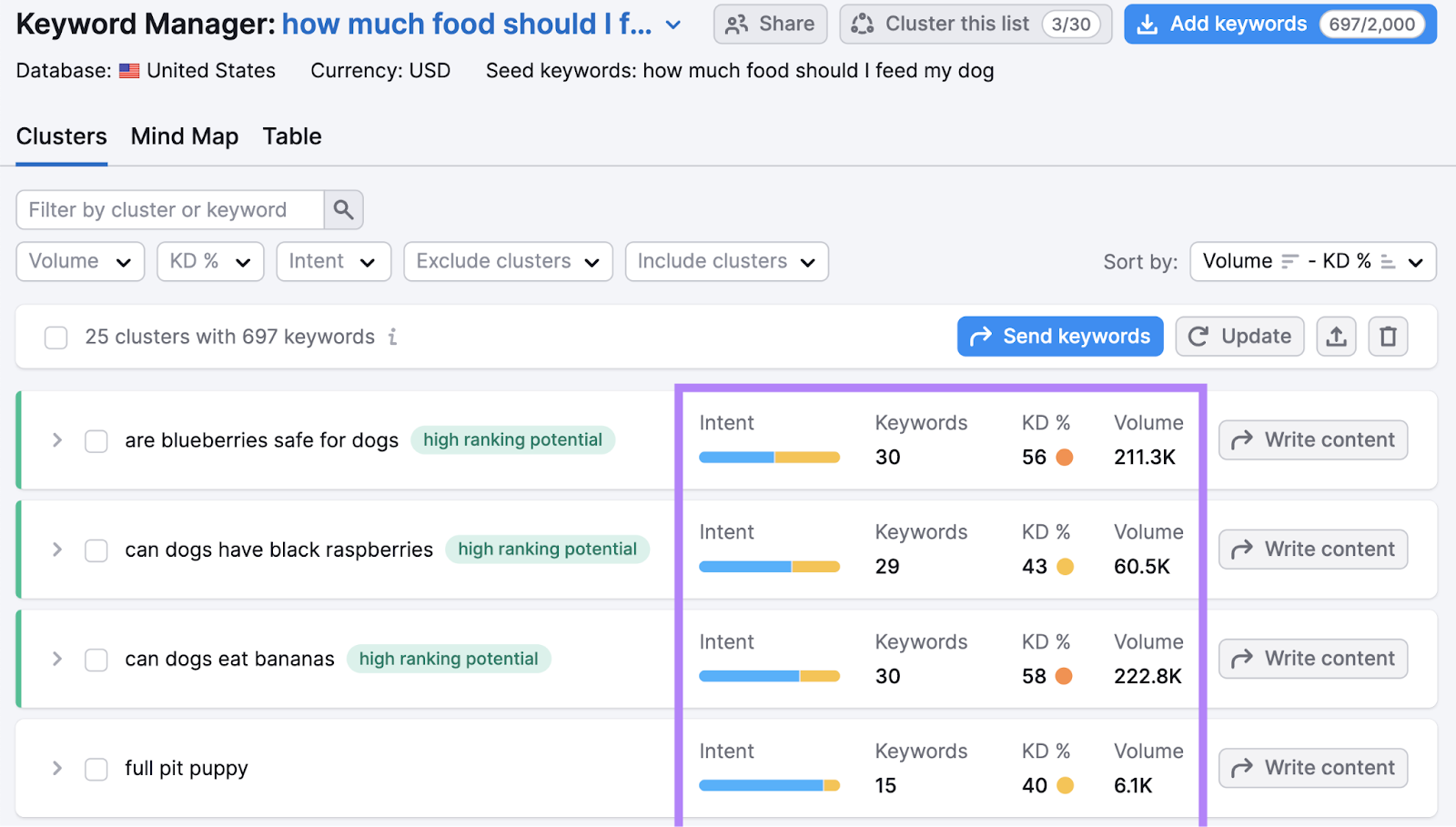
Click the arrow to see all the keywords in the cluster. And their individual metrics.
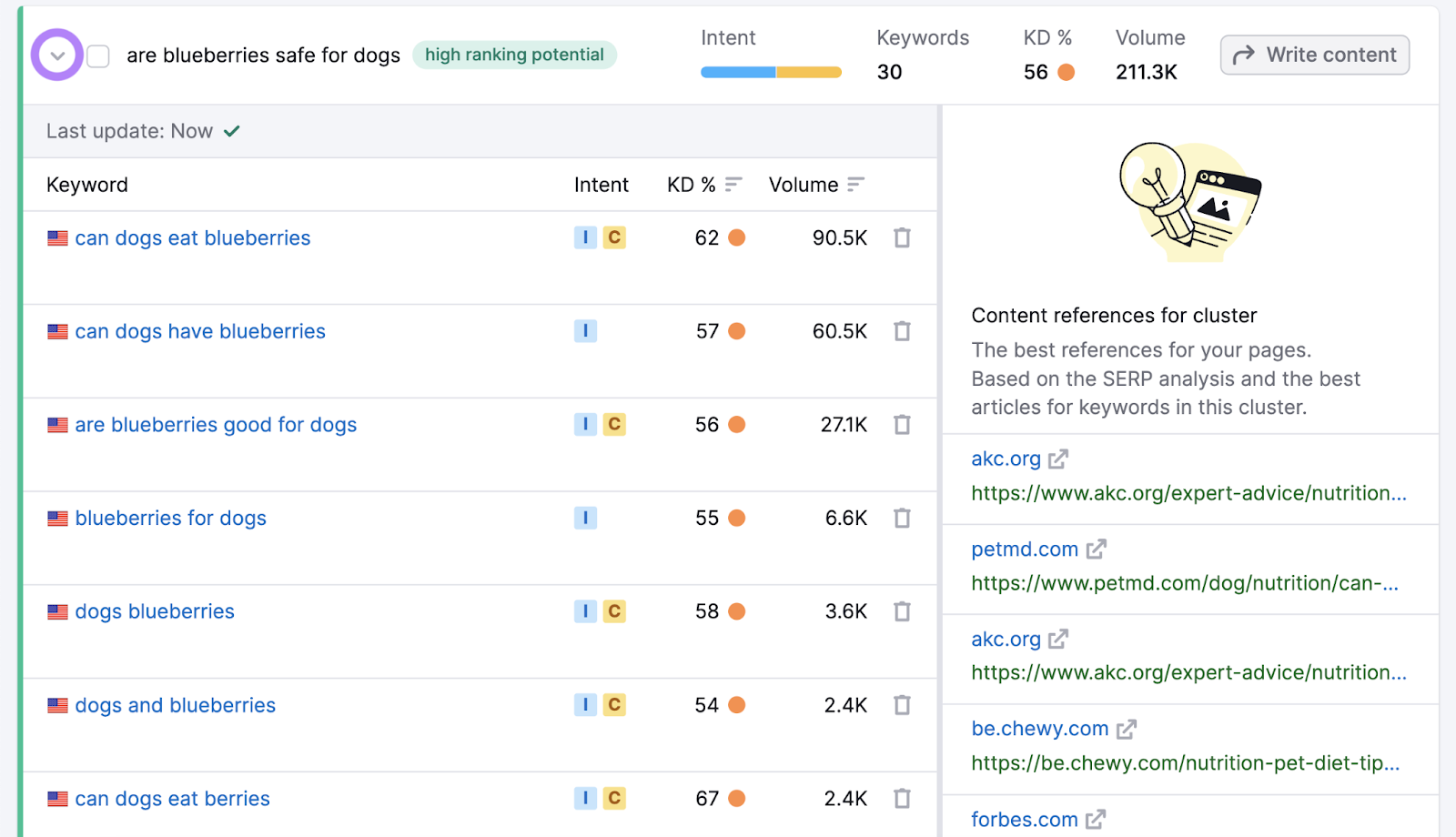
At this point, we recommend that you choose a primary keyword—the most relevant and important keyword.
This will help you to focus your optimization efforts later.
You can also start to create a keyword map that matches each cluster with its target URL (i.e., the page you want to rank).
Focus on Content Quality and Usability
Content quality is one of the most important factors in search engine rankings.
To create quality content, you generally need to:
- Satisfy search intent
- Present your content effectively
- Provide accurate and up-to-date information
- Deliver a great user experience
- Demonstrate Experience, Expertise, Authoritativeness, and Trustworthiness (E-E-A-T)
Secondly, think about how to provide added value and stand out among your competition. That might involve doing things like:
- Covering the topic more thoroughly
- Using a new, unique angle
- Providing helpful examples
- Adding original data
- Creating original media
For example, Rover’s dog feeding guide satisfies search intent by providing detailed guidelines for various kinds of dog.
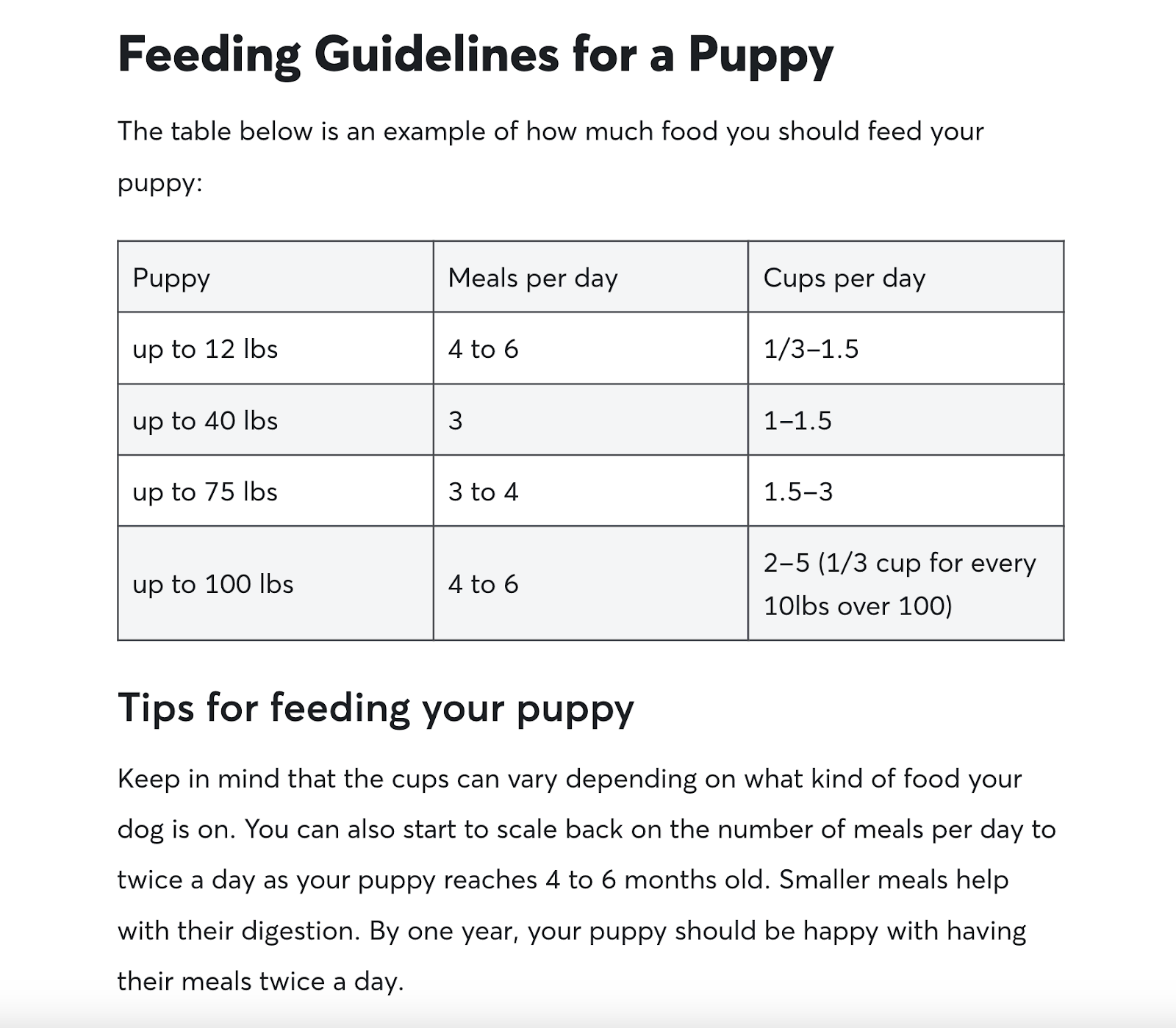
The guide also includes lots of related information and resources. Which come from reliable sources like veterinarian Dr. Jamie Whittenburg.

Rover uses subheadings, bullet points, tables, bolding, a table of contents, and other formatting tricks to make information easier to find and digest.
And even provides a video for people who prefer to get information that way.
Use Keywords Strategically
Including keywords on your page can help it rank higher. But keyword stuffing (using keywords unnaturally) can do more harm than good.
Here are some tips to help you get the balance right:
- Only include keywords where they read naturally
- Convert keywords into their correct grammatical forms (e.g., “Pedigree for small dogs” not “pedigree small dog”)
- Use your primary keyword in the:
- Body content—particularly the first paragraph
- Title tag: The page title that can appear in search results
- H1 tag: The on-page title, which should be similar or identical to the title tag
- Meta description: The page summary that can appear in search results
- URL slug: The unique part of the webpage address
- Use other (secondary) keywords within the body content and subheading tags where relevant
You can also use keywords strategically when linking to your page.
Search engines use the text used for links (anchor text) to understand what linked pages are about. This means that keyword-rich anchor text can help Google understand which pages should rank for which keywords.
For example, you might build an internal link from “/dog-food/” to “/dog-food/pedigree/” using the anchor text “Pedigree dog food.” So it’s clear which page is the most relevant result for this term.
Prioritize Keywords with Existing Rankings
Generally, it’s a good idea to optimize existing content before creating content from scratch.
Why?
- It tends to be quicker and easier
- You may have existing rankings to build upon
- The presence of poor-quality content can harm your site’s reputation and rankings
- Existing content is likely to be most relevant and important to your business
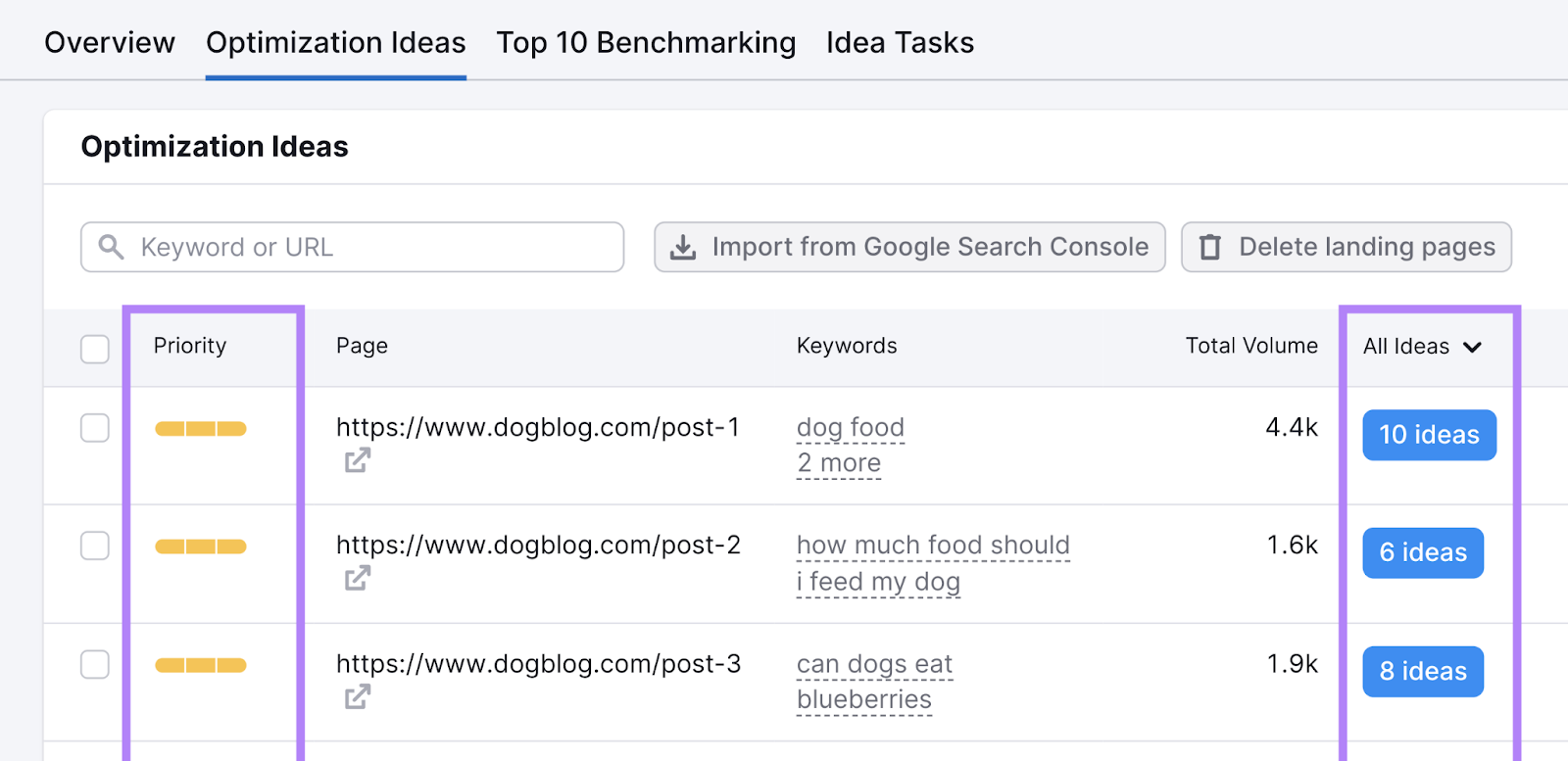
If you need help prioritizing pages and tasks, use Semrush’s On Page SEO Checker.
You set the target keyword(s) for each URL, and the tool provides:
- Optimization ideas based on best practices and top-ranking pages
- Priority ratings based on the number of ideas, keyword search volumes, and keyword difficulty scores
Advanced Keyword Research Tips
Feeling confident with what you’ve learned so far? Check out these advanced keyword research tips:
Find and Use Semantic Keywords
Semantic keywords are words and phrases that are conceptually related to a given topic.
They’re not terms that people use to search for a piece of content. They’re terms that search engines and users may expect to find within a given piece of content.
If they’re missing, it might suggest that your content is incomplete.
Let’s say you’re writing a dog feeding guide. This should probably include semantic keywords like:
- Healthy weight
- Portion size
- Senior dogs
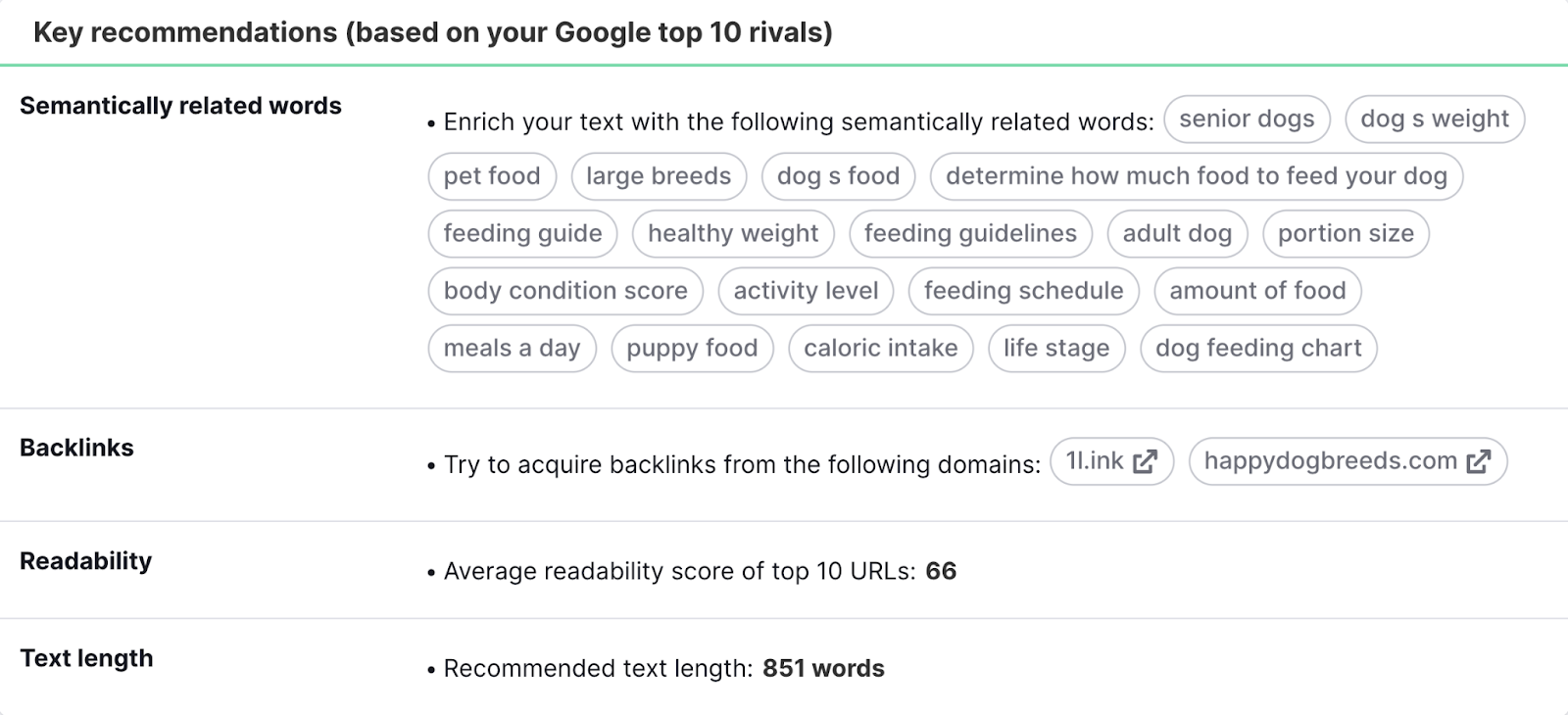
One of the best ways to find semantic keywords is with Semrush’s SEO Content Template.
It identifies semantically related keywords by analyzing the top-ranking results for your target keywords.
For example, here are the suggestions for “how much food should I feed my dog”:
Anticipate Keyword Trends
To get ahead of your competitors, try to anticipate upcoming keyword trends.
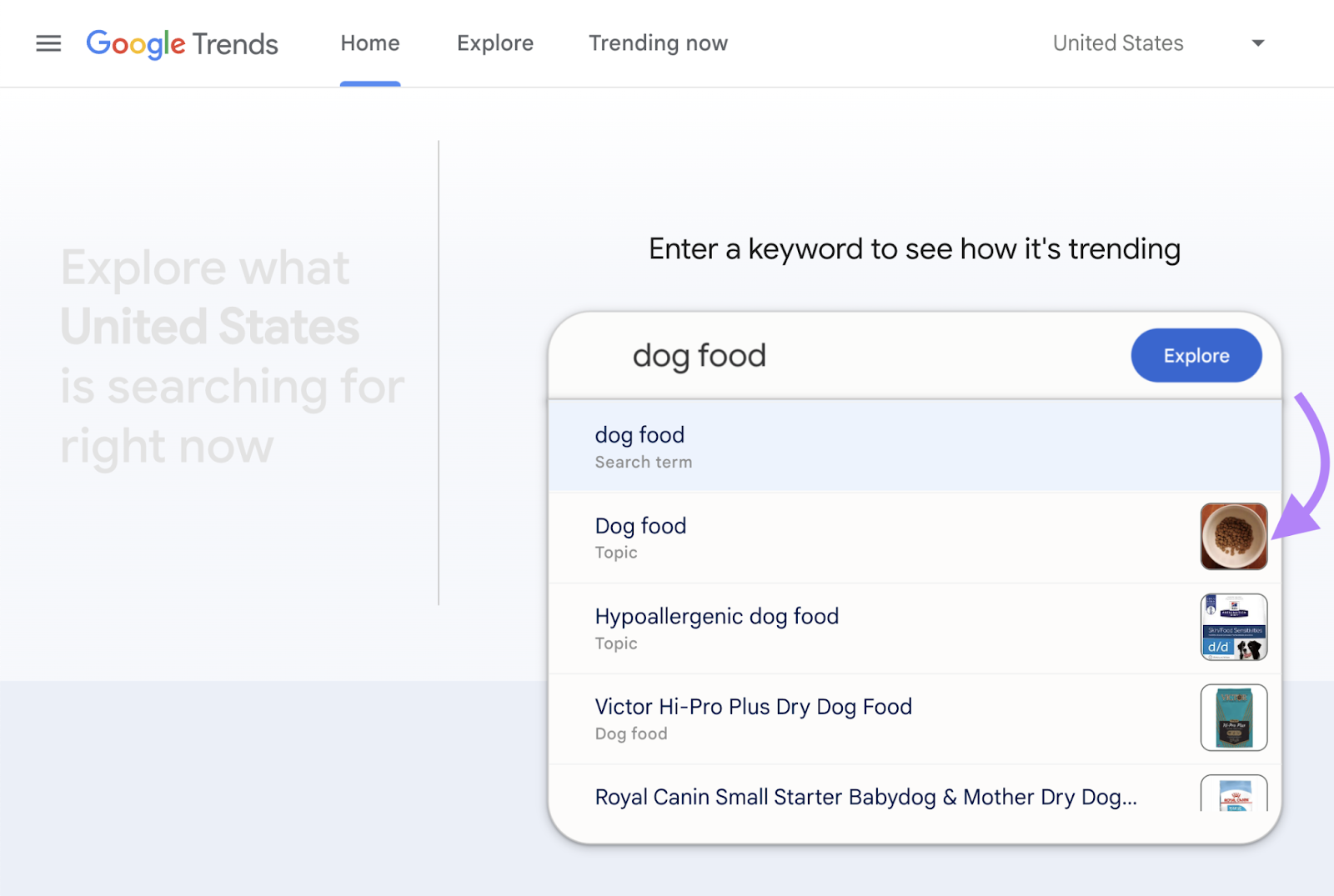
One of the best ways to do this is to use Google Trends. Because it tells you which search terms are gaining popularity.
For example, let’s explore the topic of “dog food” over the past 30 days.
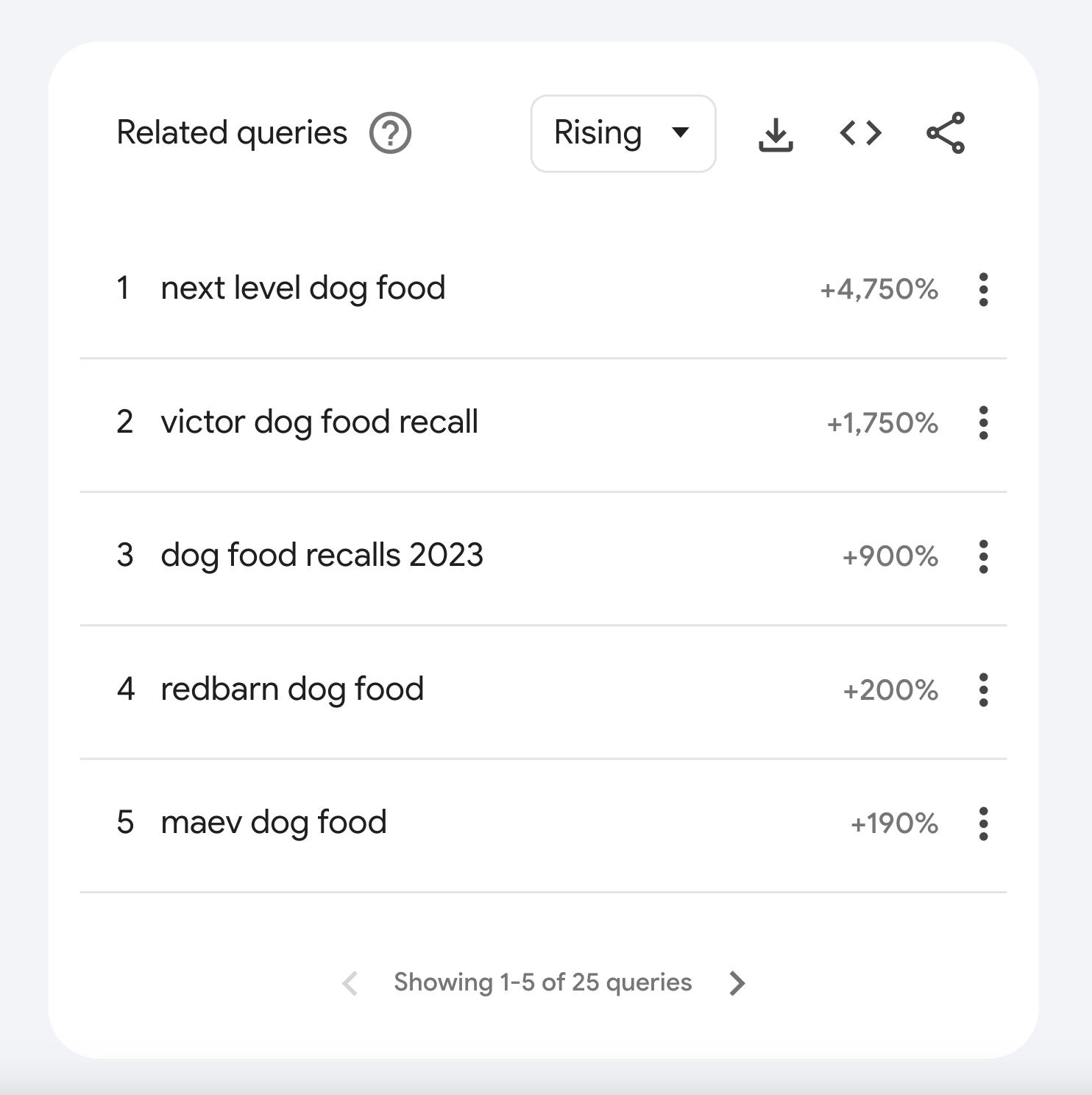
In the “Related queries” section, we can see keywords with “the biggest increase in search frequency since the last time period.”
The percentage increase is listed on the right. (“Breakout” means that it was over 5,000%.)
By quickly creating content around these keywords, you can gain valuable rankings. Before your competitors even realize the terms are popular.
You can also anticipate keyword trends by:
- Keeping up with industry news
- Seeing what relevant communities talk about on social media
- Speaking to or surveying your customers
Keyword Research Tools
We’ve already shared some options, but let’s look at some of the best and most popular tools for SEO keyword research:
Semrush Keyword Research Tools
Here’s a quick summary of Semrush’s SEO keyword research tools (many of which we’ve discussed in this guide):
- Keyword Overview: Gather metrics for up to 100 keywords at once
- Organic Research: Enter a domain or URL to see what keywords it ranks for
- Keyword Magic Tool: Use a seed keyword to search our huge keyword database
- Keyword Gap: Compare your keyword rankings against competitors’
- Keyword Manager: Save keywords into lists and create clusters automatically
- Organic Traffic Insights: Combine keyword data from Google Analytics, GSC, and Semrush
Create a free Semrush account (no credit card needed) to try them out right away. You’ll also get access to dozens of other SEO tools.
SERP Gap Analyzer
Use the SERP Gap Analyzer app to find keywords competitors rank highly for with weak content. Which reveals great opportunities to get ahead.
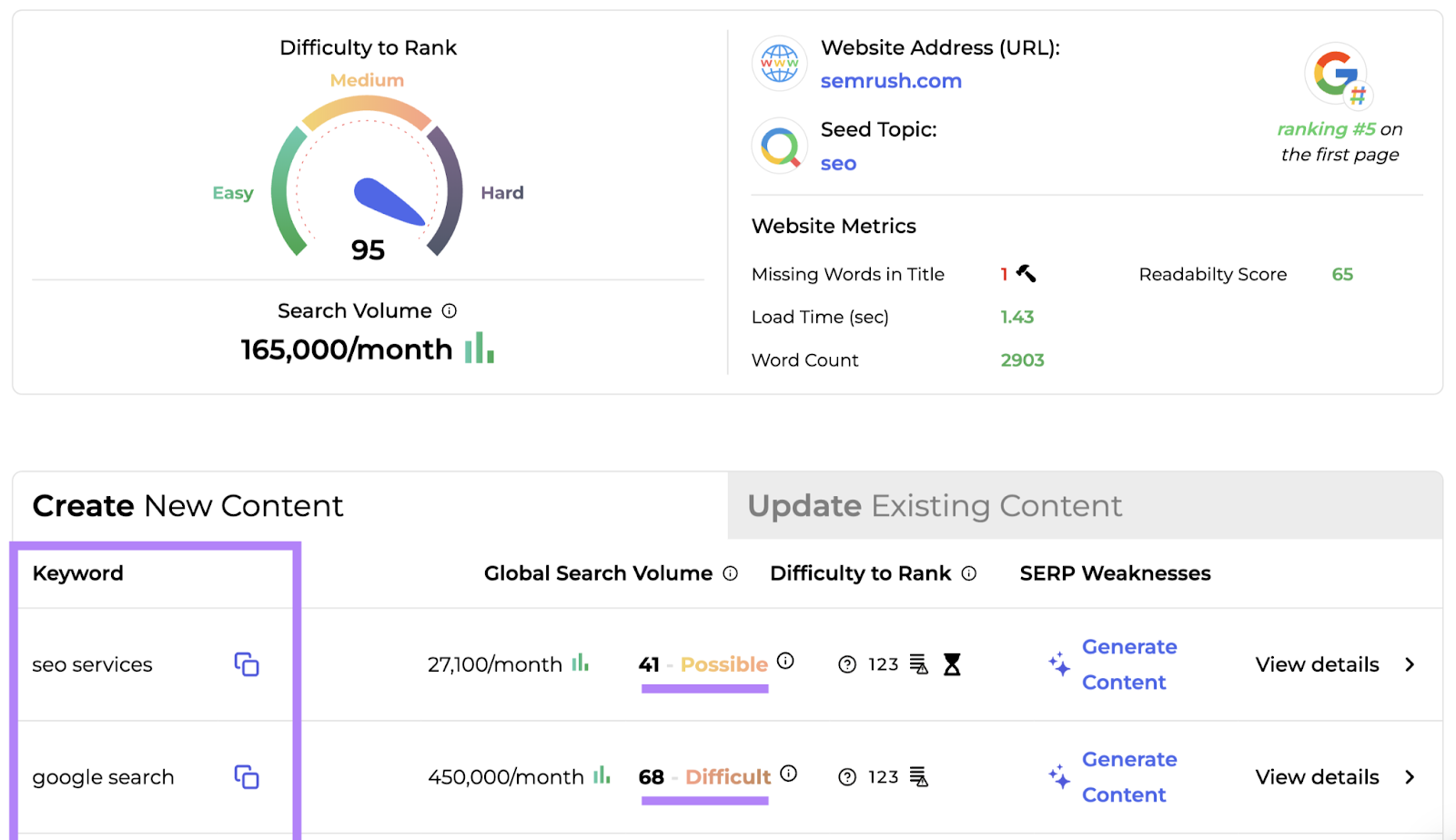
All you have to do is enter your domain and a relevant topic. Then, wait for the app to create your report.
You’ll see a variety of keyword suggestions and a difficulty rating for each:
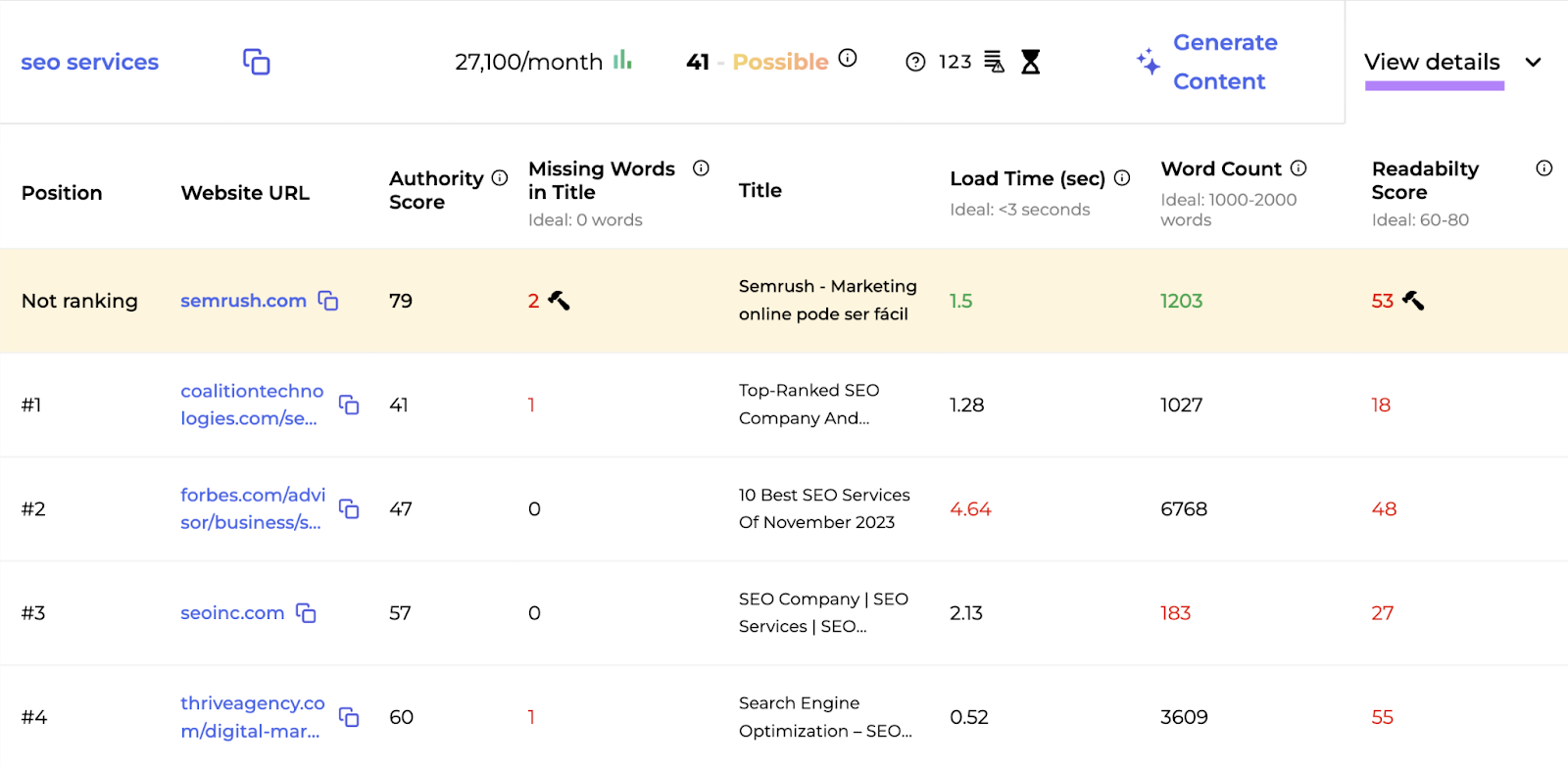
Click “View details” to see weaknesses in the top-ranking content.
This gives you a good idea of what you must do to outrank your competitors.
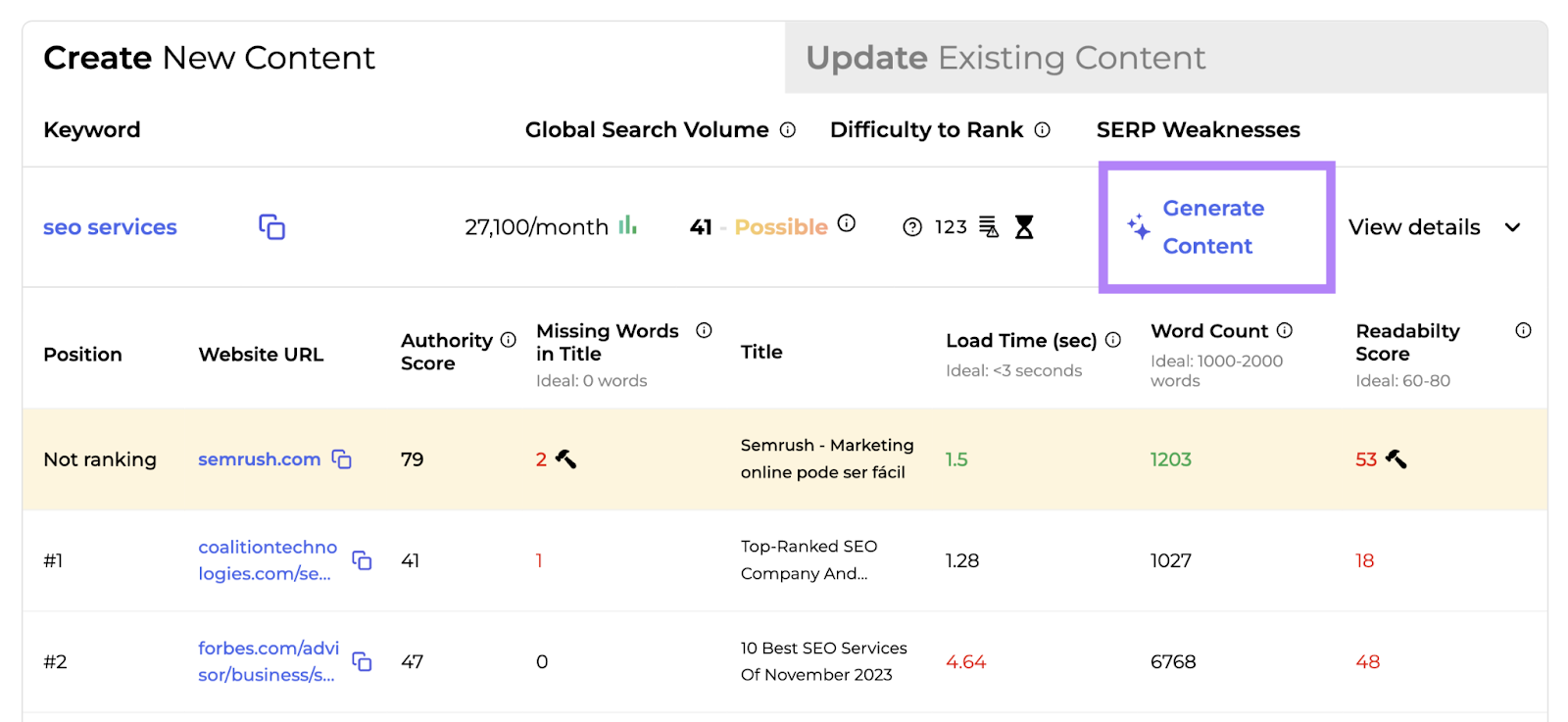
You can then click “Generate Content” to get an AI-generated title, content brief, article, or meta description for your keyword.
Google Search Console
Google Search Console (GSC) shows up to 1,000 of the most popular keywords your site ranks for.
After signing in, go to “Performance” > “Search results.” And check all the boxes at the top.

Then, scroll down to the “Queries” table.
In addition to the keywords, you’ll see the following metrics for your selected date range:
- Clicks: The number of clicks your result was clicked
- Impressions: The number of times your search result was seen
- CTR: The click-through rate, which is the percentage of impressions that generate clicks
- Position: The average ranking of your highest result for each query

Integrate GSC with your Semrush account (along with Google Analytics) to get valuable keyword insights in one place.
Google Keyword Planner
Google Keyword Planner had long been a go-to free keyword research tool for many marketers. But it’s become increasingly difficult to get exact search volume data in the tool.
Still, it can be a valuable tool if you’re on a tight budget.
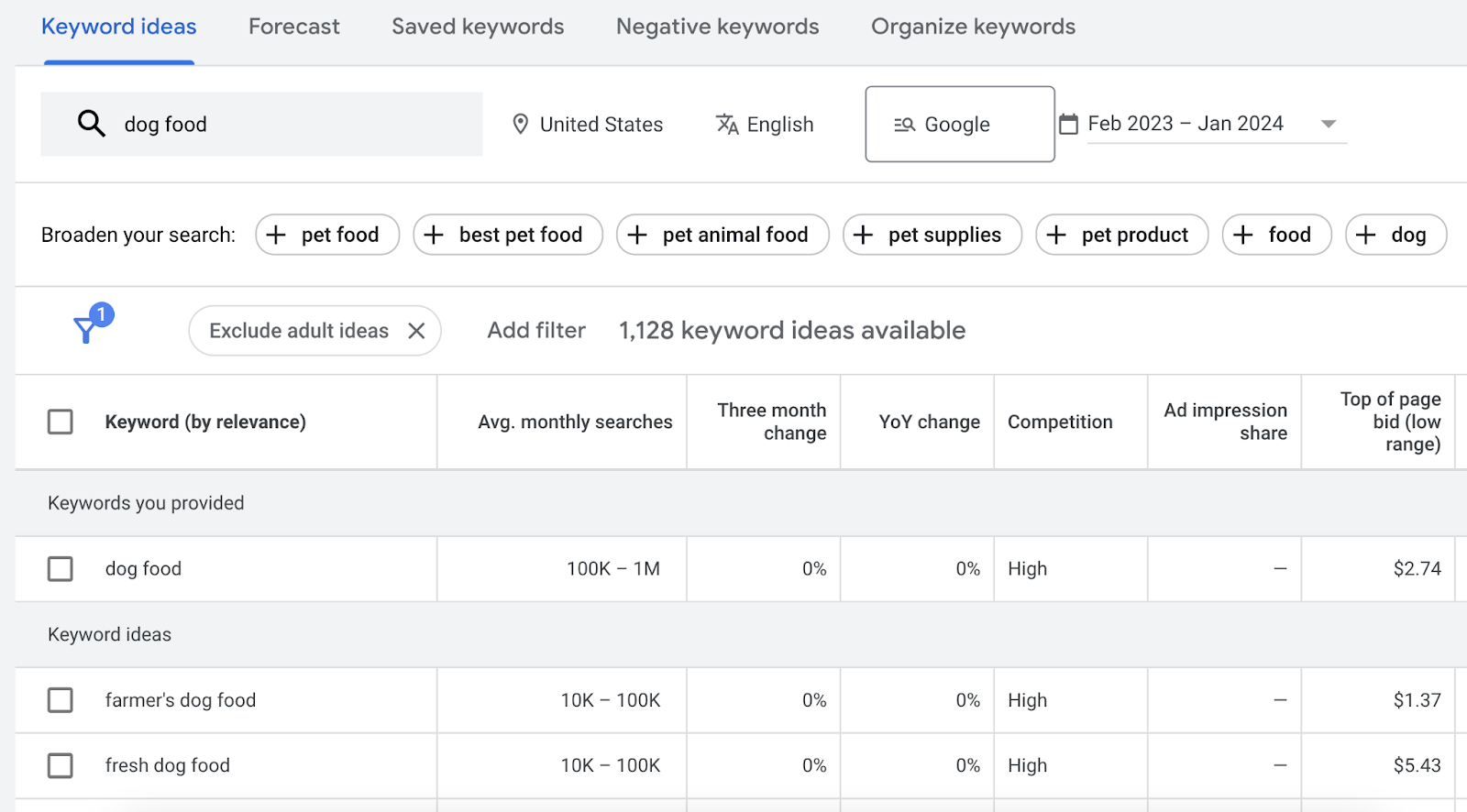
Just keep in mind that Keyword Planner is made for Google Ads users. It doesn’t provide any information about organic ranking difficulty, search intent, etc.
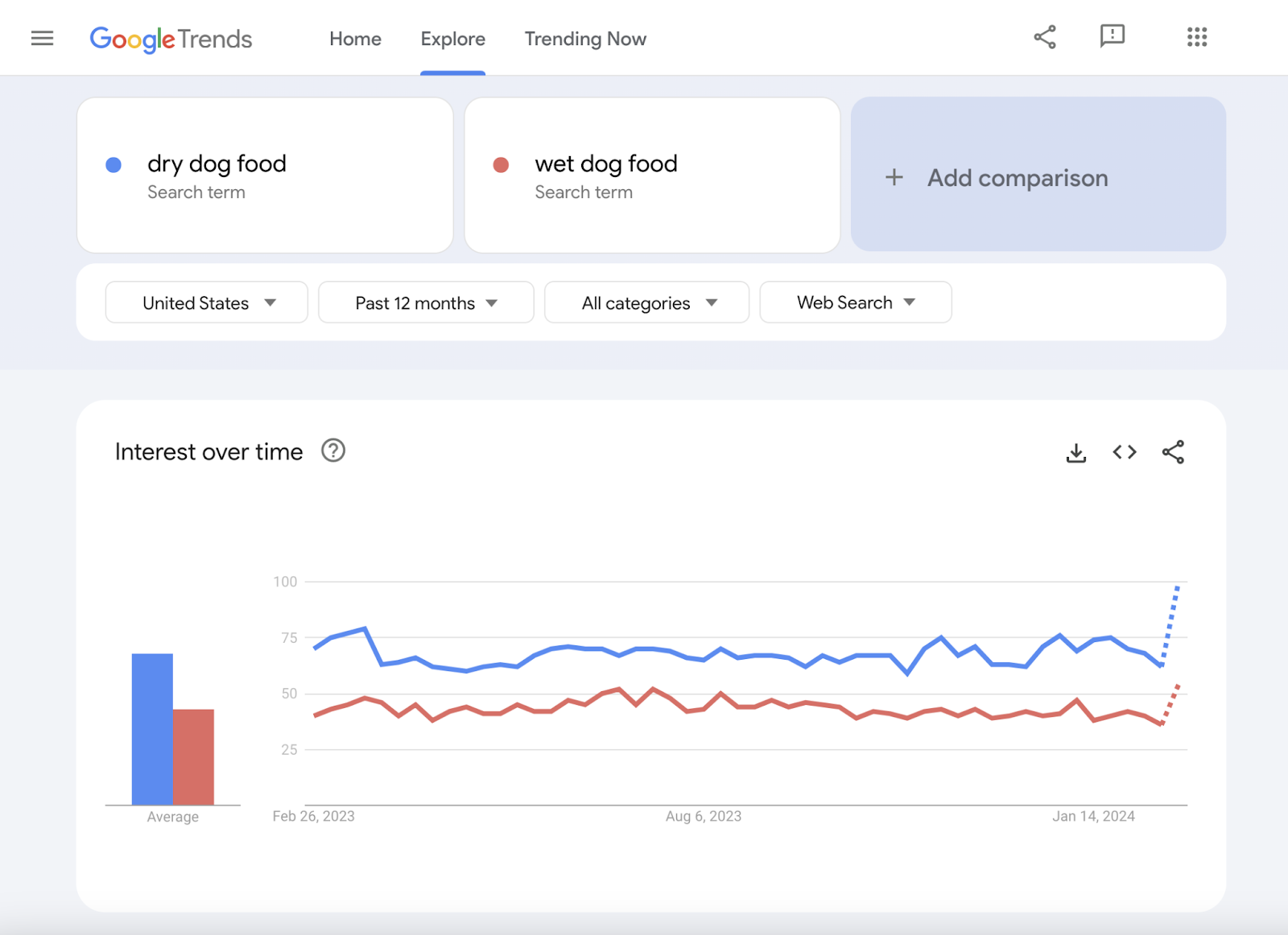
Google Trends
Although not exactly a keyword research tool, Google Trends can be very useful when it comes to:
- Finding trending topics
- Comparing the popularity of two or more products/services
- Estimating the long-term popularity of a keyword or topic
Track Your Keyword Rankings and Keep Improving
One of the best ways to measure the success of your keyword research and optimization strategy is to track your Google rankings.
Semrush’s Position Tracking tool makes it easy to see how things are going.
Just import your keywords from Keyword Manager (or elsewhere).
Then, watch how your overall visibility and individual rankings change over time.
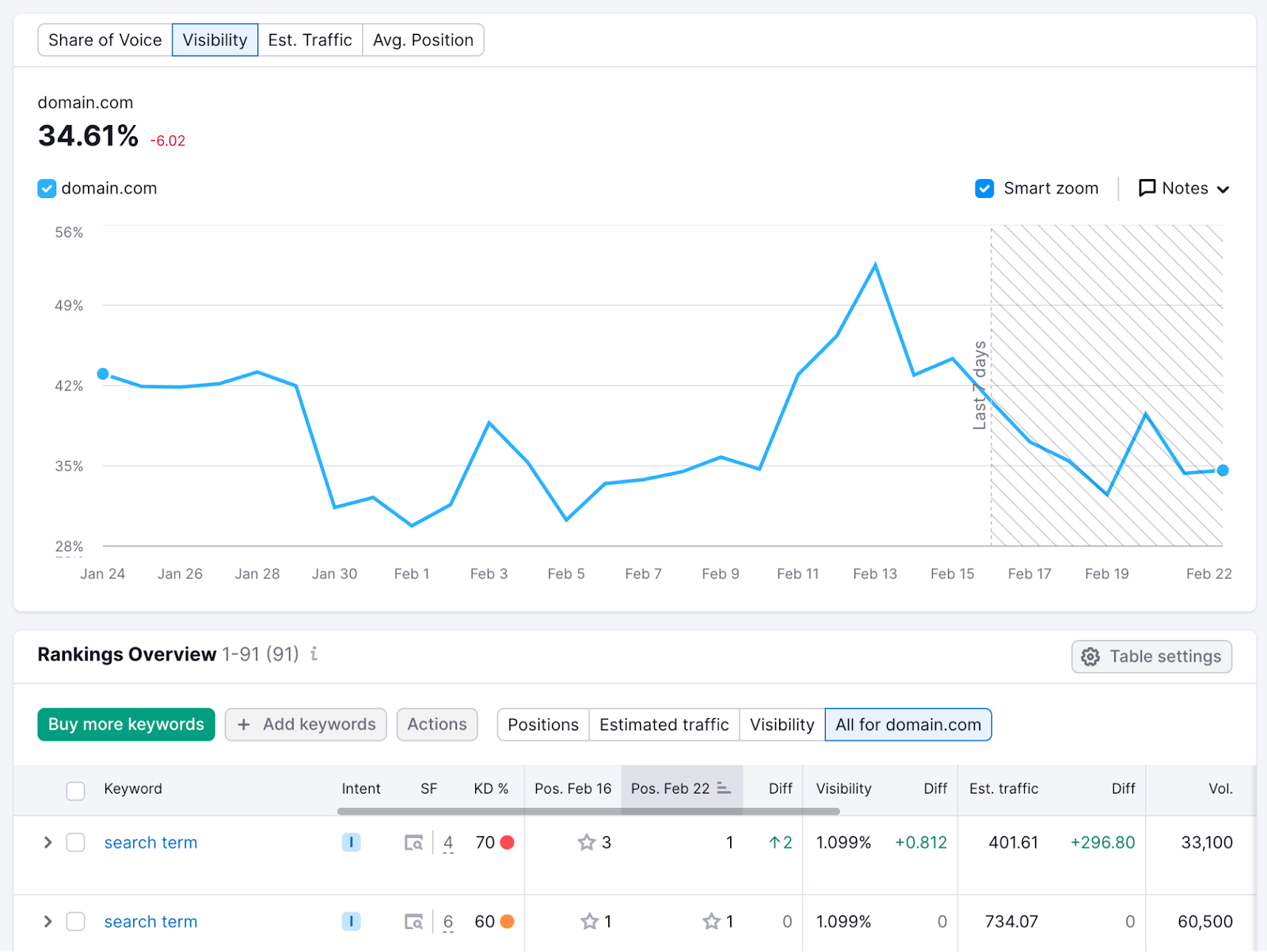
Don’t forget to keep adding new keywords as you target them.
We recommend that you conduct keyword research every few months at a minimum. So you can capitalize on new ranking opportunities and keep growing your traffic.