
What Is SEO Ranking?
SEO ranking (search engine optimization ranking) refers to a webpage’s position in search engines’ organic search results for a given search query.
If your page is higher in search results, more people are likely to see it. Which means more people may visit your site.
For example, look at Google’s top search results for the keyword “best gaming chairs.”
The first two results are paid ads. After that, one of PC Gamer’s pages holds the No. 1 organic result. This means PC Gamer has the No. 1 SEO rank on this particular search engine results page (SERP).
And it’ll likely receive more traffic than those ranking below.

Why Are Search Rankings Important?
Getting better rankings for your pages is one of the main goals of SEO. Why? Because it usually results in getting more organic traffic to your website.
To put it simply: Better rankings = more visitors.
This also serves your strategic marketing and business goals, such as:
- Increased brand awareness: Higher search rankings make your website more visible, allowing more people to discover and learn about your business. This boosts brand recognition and trust over time.
- More sales: More visitors naturally leads to more sales and conversions, as a percentage of those visitors will likely purchase your products or services
- Lower customer acquisition costs: Organic traffic is essentially free, especially compared to other paid advertising channels. Higher organic traffic volumes lower your overall cost of acquiring customers over the lifetime of your business.
Because of all these benefits, having higher search rankings is extremely important today.
How to See Your SEO Rankings
Before you learn how search engines rank pages and how you can improve your own rankings, you need to know where you currently stand.
Why?
When you understand where you presently rank for important keywords, you create a baseline to measure progress against.
Without knowing your starting point, you can't set proper goals or quantify the impact of optimizations.
There are two main ways to check your current search engine rankings in Google.
Check Google SERPs
The most direct way is to simply search for your target keywords in Google and see where your pages appear in the results.
This shows you the actual live ranking position. However, manually checking rankings this way is very time-consuming and inefficient.
That’s why it’s better to use a software tool that can track your keyword rankings automatically and provide you with detailed reports and insights.
Use Position Tracking Tool
Semrush’s Position Tracking tool is a robust automated solution for rank tracking.
Key features include:
- Track thousands of keywords on a daily basis
- Email alerts for ranking changes
- Building ranking history databases to spot trends
To get started, set up a project in the tool and add the keywords you want to track.
Once done, the tool will show you your current rankings. Just go to the “Overview” tab and scroll down to find the “Rankings overview” section.

After you see your current positions, you can think about improving.
To improve your SEO rankings, you need to first understand how search engines rank pages.
After all, if you don't understand what factors search engines use to rank pages, how can you properly optimize your site?
You'd just be guessing blindly instead of strategizing effectively.
How Search Engines Rank Pages
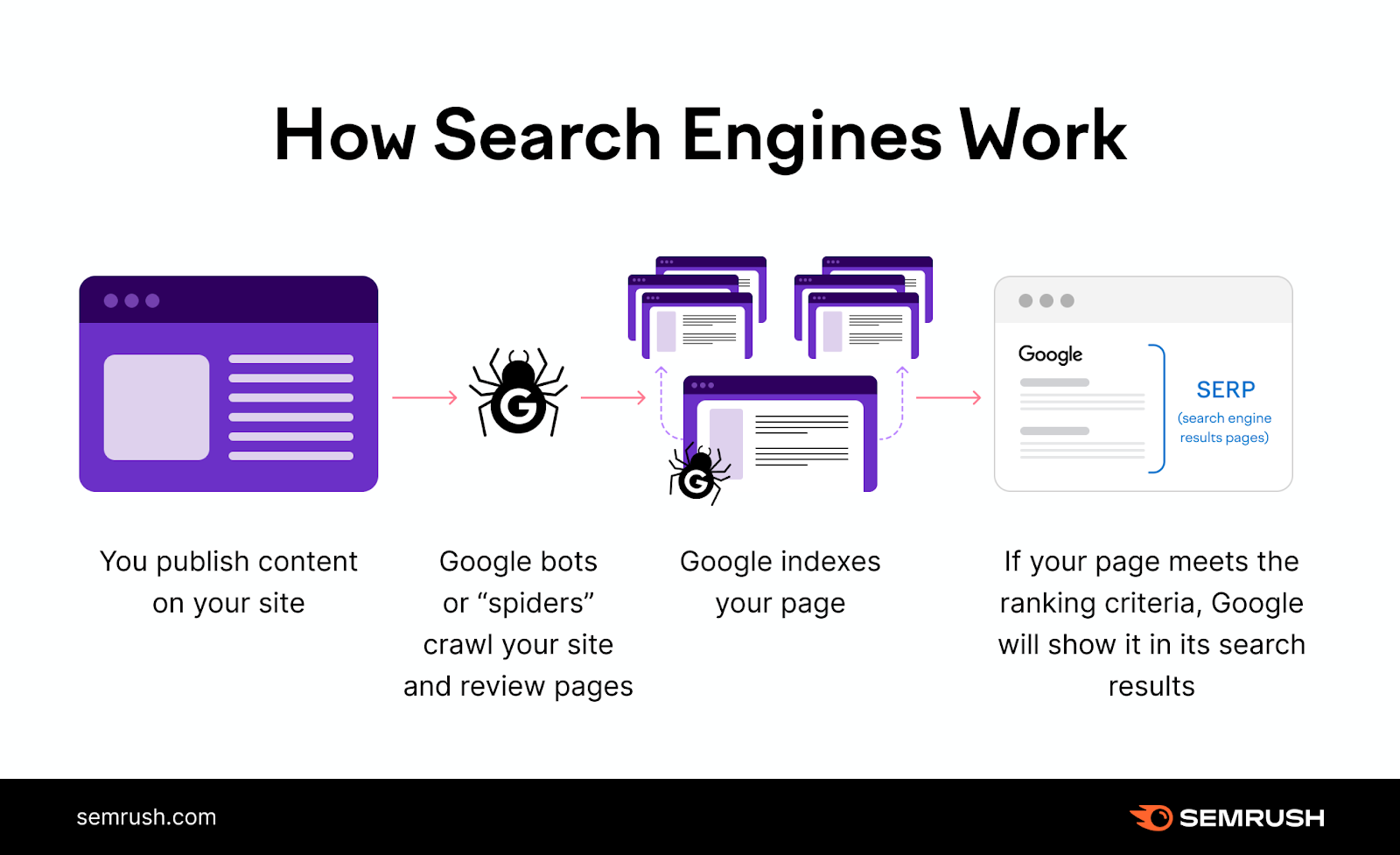
To rank your pages, search engines need to discover them first.
Let’s take a look at how this process works in Google:
- Crawling: First, Googlebot (a web crawler) will crawl your site. That means it goes from one page to another and “reads” the content.
- Indexing: Then, Google stores information about your pages in a huge database called the Google index.
- Ranking: If the page meets Google’s criteria, it will be served as a search result for relevant search queries.
Google Ranking Algorithms
Your Google SEO rankings depend solely on the search engine’s algorithms.
Google’s algorithms are a set of complex internal processes used by Google to rank pages.
Here are some basic facts we know about Google's algorithms:
- Google calls these algorithms “ranking systems”
- Many of the ranking systems apply to all search queries
- Some systems are only used for specific types of queries. For example, the product reviews system only applies to the ranking of product review pages.
- The algorithms take into consideration a huge number of ranking factors and signals
- The algorithms are being updated constantly. The smaller updates happen on a daily basis. The bigger Google algorithm updates (also called “core” algorithm updates) happen several times a year.
Examples of Confirmed Ranking Factors
No one knows exactly all the factors search engines like Google consider when ranking pages.
Some have been confirmed. Some are thought to be factors by most SEO experts (although not officially confirmed). And some are pure speculation.
All we know for sure is that there are many SEO factors that influence your rankings either directly or indirectly. We’ll discuss some of them below.
Over the years, Google has officially confirmed the importance of several factors. Here are some examples of SEO factors Google has confirmed:
- Content relevance: Google determines whether a page is relevant to a search query and ranks the most relevant pages (source)
- Content quality: Google uses various means to identify quality in order to rank pages (source). This includes input from real people and machine learning algorithms.
- Backlinks: Relevant links from other sites help Google identify trustworthiness (namely through the PageRank algorithm), as well as relevance (source, source)
- Physical proximity: Google considers how far a business is from the searcher's location for local search results (source)
- Mobile-friendliness: Pages optimized for mobile devices may rank better in Google's mobile search results (source)
- Page performance: Google uses a set of metrics called Core Web Vitals to determine how well a page performs in terms of speed, responsiveness, and visual stability (source, source)
- HTTPS: Google detects whether a website uses a secured, encrypted connection and gives a slight advantage to those that do (source)
There are also some negative ranking factors.
The presence of these on a website may lead to worse rankings or even penalties from Google:
- Intrusive pop-ups: Using pop-ups that prevent users from accessing the content on mobile devices (source)
- Keyword stuffing: Using irrelevant keywords or excessive usage of certain keywords (source)
- Unnatural links: Any attempt to manipulate PageRank (including link buying, link exchanges, low-quality links, etc.) (source)
Please note that these are just examples of ranking signals Google uses. No one knows all of them. Or their exact levels of importance.
Google tends to limit information about how exactly their ranking algorithms work.
Mainly because the algorithms are their proprietary business information. Also, if all the ranking factors were publicly available, it would be easier to cheat your way to better rankings.
Correlation vs. Causation
It’s important to distinguish between correlation and causation in the context of SEO factors.
A high correlation between a certain SEO factor and higher rankings does not necessarily imply causation.
A typical example would be word count.
Some SEO studies have previously observed that pages with more words tend to rank higher.
However, it doesn’t necessarily mean that Google uses word count as a direct ranking factor. (In fact, it almost certainly doesn’t.) That being said, long-form content can still help you get better rankings.
Mainly because:
- It covers the topic more comprehensively (improving the content’s relevance and quality)
- It can attract more backlinks (improving the content’s PageRank)
How to Improve Your SEO Rankings
To improve your SEO rankings, we recommend taking a holistic approach to search engine optimization.
Don’t focus on just one factor (for example, getting more backlinks). Instead, take a comprehensive look at all the aspects of your website’s SEO. And try to improve in all the main areas.

Let’s take a look at the basic areas you need to improve in order to rank better.
We’ll also provide actionable tips on how to use Semrush tools in each step. Feel free to create a free account (no credit card needed) so you can follow along.
Conduct Keyword Research
Keyword research is the process of finding and analyzing keywords you want to rank for.
It will help you pick the most effective keywords, based primarily on the following criteria:
- Search volume: How many times are people searching for the keyword each month, on average?
- Keyword difficulty: How fierce is the competition ranking for the keyword?
- Search intent: What is the reason users are searching for the keyword?
Search intent is particularly crucial when it comes to your search rankings. Google pays a lot of attention to the search intent behind each query and tries to serve the most relevant results.
Do users want to navigate to a specific page? Purchase a product? Find a specific piece of information?
Say someone searches, “best flowers for valentine’s day.” This user is doing research and wants to learn what kind of flowers they should purchase.
But if they search for “valentine’s day flowers near me,” they want to find and purchase flowers.
The SERPs will differ significantly between these two keywords. While the first keyword returns blog posts about Valentine’s Day flowers, the second SERP features mostly flower shops and flower delivery services.

Choosing the right keywords and understanding the intent behind them will help you ensure your content is relevant to the search queries.
To conduct keyword research, you’ll need a keyword research tool.
Semrush’s Keyword Magic Tool will give you both keyword ideas and the metrics mentioned above.
Enter your first keyword into the tool and hit “Search.”
It can be a general keyword. If you’re doing keyword research for a florist, you might choose “flowers.”

The tool will then provide thousands of keyword suggestions with additional details for each of them.
The three key metrics—search intent (“Intent”), search volume (“Volume”), and keyword difficulty (“KD%”)—are also available.

To narrow down the results, use filters.
For example, you can choose to only show keywords that are in the form of a question. Or keywords that have at least 500 monthly searches. Or keywords with transactional search intent. Or all of the above at once.

You can further explore the keyword groups and subgroups that will help you identify the most common topics within your niche and help you map your keywords.

Read our detailed guide to keyword research to learn more about the process.
Create Quality Content
Content quality is at the heart of SEO. In most niches, the competition is so fierce that you won’t rank well at all if your content is just average.
Your content has to be great.
But how do you define quality content?
First, your content has to be comprehensive. This means it answers all the questions a user may have about the target topic.
Let’s say a user searches for “bonsai tree care.”
Of course, they want to know the basics. Like how often to water the tree and which fertilizers to use.
But they’ll probably also appreciate it if the post answers some further questions. Like when repotting is needed or what the difference is between caring for indoor and outdoor trees.
A great way to ensure your content stands out is to analyze your competitors.
Enter your target keyword into Semrush’s SEO Content Template tool to get an overview of the SERP for any location.

Then, explore the top-ranking pages:

Click the links to the best-performing competitors’ pages and see how they covered the topic.
You’ll also get a list of semantically related keywords. This can help you see to what extent your competitors have covered your target topic. By seeing the most common related keywords they used.

Secondly, your content has to be reliable.
Google employs thousands of people—called Quality Raters—who go through the search results and rate pages based on Google’s quality guidelines.
Within these guidelines, Google defines a set of signals commonly referred to as E-E-A-T. The acronym stands for:
- Experience: You should demonstrate relevant, firsthand experience with the subject matter
- Expertise: You should be an expert in the field you write about
- Authoritativeness: Your website should be an authoritative source (ideally mentioned on other authoritative websites in your niche)
- Trustworthiness: Your website should demonstrate trust (citing sources, using author credentials, etc.)
Although the input by Quality Raters does not impact rankings directly, it is used to feed Google’s systems to recognize quality content better.
High-quality content should be unique, too. It means providing all (or at least some) of the following:
- Original angle
- Original data (studies, polls, etc.)
- Original media (illustrations, videos, etc.)
- Original examples
Unique content will demonstrate quality to Google, but there’s another benefit: It can also help you attract backlinks naturally. (More on backlinks in the next section.)
Your content should also be up to date. In fact, content freshness can be a ranking factor for time-sensitive queries.
Last but not least, great content must be easy to read.
Most people just scan through webpages nowadays. Make sure your content is structured in a way that is easy to skim.
You can check your content’s readability with Semrush’s SEO Writing Assistant. This tool will analyze your content and provide scores and recommendations for these four categories:
- Readability: Provides readability score, recommends word count, and suggests improvements
- SEO: Checks for relevant keyword usage and highlights some on-page issues (missing alt text, broken links, etc.)
- Tone of voice: Analyzes the tone of the text, checks for consistency, and lists most formal and most casual sentences
- Originality: Checks your text for any signs of plagiarism

Type your text directly into the tool or import existing text from the web. You can also use the SEO Writing Assistant as a Google Docs or Microsoft Office extension, as well as a WordPress plugin.

This will allow you to edit your text and get recommendations in real time, directly in your preferred editor.
Let’s say the tone of voice of your text is too formal. Simply click on “Tone of voice” in the sidebar navigation. And scroll down to review the list of “Most formal sentences” provided by the tool.

If you click a sentence in the list, the tool will show you where it appears in your text. And you can rewrite it to sound more casual.
The SEO Writing Assistant will immediately reflect the changes in the updated analysis results.
Get Quality Backlinks
Backlinks have helped Google rank pages since the very beginning.
The idea behind backlinks as an indicator of quality is simple:
If many high-authority pages link to your page, it’s a good indication that your page is also a reliable, high-quality source.
And Google will reward you with higher rankings for that.
There are many ways you can get more backlinks. (This process is called link building.) But you need to be careful—Google prohibits any link manipulation, especially buying links.
A good way to start is to look at your competitors’ backlinks.
Just enter your domain and the domains of your top competitors in the Backlink Gap tool. Then, hit “Find prospects.”

In a matter of seconds, you’ll be able to see domains that link to your competitors (but not you).

You can then explore specific pages that contain backlinks to your competitors. Then save these pages for email outreach.
Just select the domain by checking the box next to it and clicking the “Start outreach” button in the top-right corner.

This will move the backlink prospects to the Link Building Tool, where you can manage your email outreach.
To dive deeper into this technique, read our step-by-step guide on how to replicate the backlinks of your competitors.
Improve Your Technical SEO
Technical SEO means optimizing all the technical aspects of your website. Its main goal is to ensure Google and other search engines can crawl and index your website correctly.
Here are a few main categories of technical SEO:
- Improving site architecture and navigation
- Speeding up your website
- Ensuring mobile-friendliness
- Using correct on-page SEO elements
- Fixing common issues (like duplicate content, HTTP issues, redirect errors, etc.)
We recommend conducting a complete technical SEO audit to identify the most serious issues.
Semrush’s Site Audit tool can help with that.
Once you create your project and set up the first crawl, you’ll get a complete overview of your website’s overall health.

You can then explore various aspects of your technical SEO through the “Thematic Reports”:

Or simply switch to the “Issues” tab. Here, you’ll see all the issues the tool has detected on your site.

Go through them and start fixing them one by one. The issues are listed in order of their severity—so you can start at the top with the “Errors.”
Besides the list of affected pages for each issue, you’ll also get a description and tips on how to fix it. Just click the “Why and how to fix it” link next to the name of the issue.

For more information, read our detailed guide on how to conduct a technical SEO audit.
Monitor Your Progress
Now that you’ve made several efforts to improve your SEO rankings, it's important to continuously monitor your progress.
This will help you understand whether your efforts are yielding results. Or if you need to adjust strategy.
Use Semrush’s Position Tracking tool to monitor ranking of your keywords.
Open the tool.
You can either create a new project or use an existing project. To create a new project, click the “+ Create project” button in the top-right corner.

Then, enter your domain and the project name.

Once you’ve created a project, you can set up the tracking.
Choose campaign settings for the following in the “Targeting” section:
- Search engine (Google or Baidu)
- Device (mobile or desktop)
- Target location
- Language

And then click “Continue To Keywords → .”
In the “Keywords” section, you'll enter the keywords you want to monitor. You can do that manually or import the list.
Once you’ve entered all your keywords, hit the “Start Tracking” button. (Of course, you can add new keywords to the tracking anytime in the future.)

In the “Landscape” report, the tool will provide a detailed analysis of your overall progress. As well as key metrics and the rankings distribution chart.

The “Overview” tab will track your rankings over time—for overall search visibility and individual keywords.

You can dive deeper by exploring the tool's various reports.
For example, the “Competitors Discovery” report will allow you to analyze your top organic search competitors, add them to your tracking, and see how your rankings compare for popular keywords.

Last but not least, you can set up alerts to stay informed about any significant changes in your rankings.
Just click the little bell icon in the top-right corner and set up your first trigger. For example, you could get a notification every time one of your keywords leaves the top three positions.

Read our detailed guide to learn more about Google keyword ranking.