What Is JavaScript SEO?
JavaScript SEO is a part of technical SEO that focuses on making websites built with JavaScript easier for search engines to crawl, render, and index.
Common tasks include the following:
- Optimizing content injected via JavaScript
- Correctly implementing lazy loading
- Following internal linking best practices
- Preventing, finding, and fixing JavaScript issues
And others.
Note: If you need to refresh your knowledge about basic JS, read our guide: What Is JavaScript & What Do You Use It For?
How Does Google Crawl and Index JavaScript?
Google processes JS in three phases:
- Crawling
- Rendering
- Indexing

Google’s web crawler (known as Googlebot) queues pages for crawling and rendering.
It crawls every URL in the queue.
Googlebot makes a request. Then the server sends the HTML document.
Next, Googlebot decides which resources it needs to render the page’s content.
This means it crawls the HTML. Not JS or CSS files because rendering JavaScript requires immense resources.
Think about all the computing power Googlebot needs to download, read, and run JS for trillions of pages on nearly 2 billion websites.
So, Google defers rendering JavaScript. It queues anything unexecuted to process later as resources become available.
Once resources allow, a headless Chromium (Chrome browser without a user interface) renders the page and executes the JavaScript.
Googlebot processes the rendered HTML again for links. And queues the URLs it finds for crawling.
In the final step, Google uses the rendered HTML to index the page.
Server-Side Rendering vs. Client-Side Rendering vs. Dynamic Rendering
Google JavaScript indexing issues are largely based on how your site renders this code: server-side, client-side, or dynamic rendering.
Server-Side Rendering
Server-side rendering (SSR) is when JavaScript is rendered on the server. A rendered HTML page is then served to the client (browser, Googlebot, etc.).
For example, when you visit a website, your browser makes a request to the server that holds the website’s content.
Once the request is processed, your browser returns the rendered HTML and shows it on your screen.
SSR tends to help pages with SEO performance because:
- It can reduce the time it takes for a page’s main content to load
- It can reduce layout shifts that harm the user experience
However, SSR can increase the amount of time it takes for your page to allow user inputs.
Which is why some websites that deal heavily in JS opt to use SSR for some pages and not others.
Under hybrid models like that, SSR is usually reserved for pages that matter for SEO purposes. And client-side rendering (CSR) is usually reserved for pages that require a lot of user interaction and inputs.
But implementing SSR is often complex and challenging for developers.
Still, there are tools to help implement SSR:
- Gatsby and Next.JS for the React framework
- Angular Universal for the Angular framework
- Nuxt.js for the Vue.js framework
Read this guide to learn more about setting up server-side rendering.
Client-Side Rendering
CSR is the opposite of SSR. In this case, JavaScript is rendered on the client side (browser or Googlebot, in this case) using the Document Object Model (DOM).
Rather than receiving the content from the HTML document as in server-side rendering, you get a bare-bones HTML with a JavaScript file that renders the rest of the site using the browser.
Most websites that use CSR have complex user interfaces or many interactions.
Check out this guide to learn more about how to set up client-side rendering.
Dynamic Rendering
Dynamic Rendering is an alternative to server-side rendering.
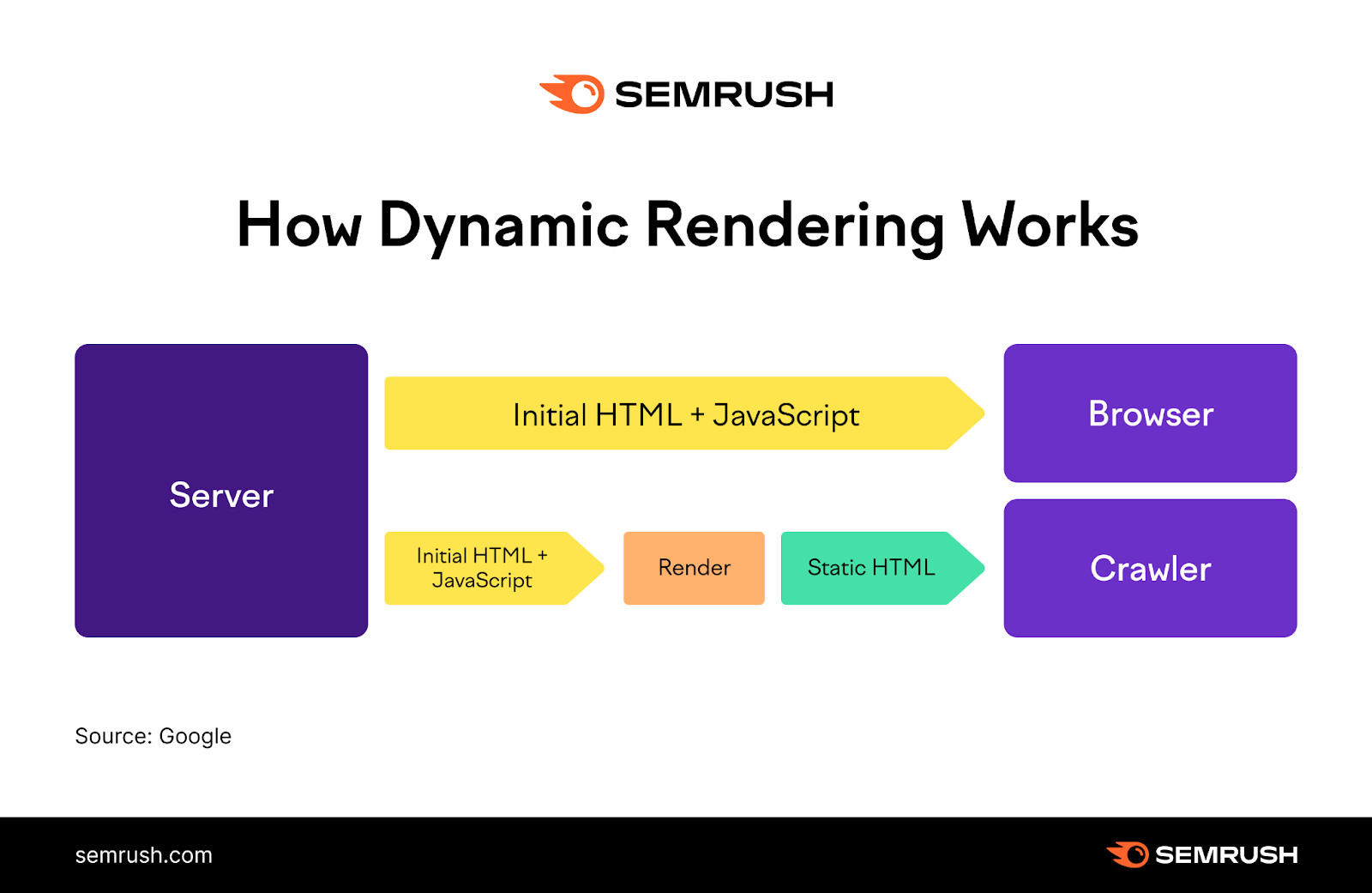
It detects bots that may have problems with JS-generated content and delivers a server-rendered version without JavaScript.
All while showing users the client-side rendered version.
Dynamic rendering is a workaround and not a solution Google recommends. It creates additional, unnecessary complexities and resources for Google.
You might consider using dynamic rendering if you have a large site with content that changes rapidly and needs quick indexing.
Or if your site relies on social media and chat apps that need access to a page’s content.
Or if the crawlers important to your site cannot support some of the features of your JS.
But really, dynamic rendering is rarely a long-term solution. You can learn more about setting up dynamic rendering and some alternative approaches from Google’s guidelines.
Note: Google generally does not consider dynamic rendering to be “cloaking” (the act of presenting different content to search engines and users). While dynamic rendering isn’t ideal for other reasons, it’s unlikely to violate the cloaking rules outlined in Google’s spam policies.
How to Make Your Website’s JavaScript Content SEO-Friendly
You can follow several steps to ensure search engines properly crawl, render, and index your JS content.
Use Google Search Console to Find Errors
Googlebot is based on Chrome’s latest version. But it doesn’t behave the same way as a browser.
Which means launching your site doesn’t guarantee Google can render its content.
The URL Inspection Tool in Google Search Console (GSC) can check whether Google can render your pages.
Enter the URL of the page you want to test at the very top. And hit enter.

Then, click on the “Test Live URL” button on the far right.

After a minute or two, the tool will show a “Live Test” tab. Now, click “View Tested Page,” and you’ll see the page’s code and a screenshot.

Check for any discrepancies or missing content by clicking on the “More Info” tab.

A common reason Google can’t render JS pages is because your site’s robots.txt file blocks the rendering. Often accidentally.
Add the following code to the robot.txt file to ensure no crucial resources are blocked from being crawled:
User-Agent: Googlebot
Allow: .js
Allow: .cssNote: Google doesn’t index .js or .css files in the search results. They’re used to render a webpage.
There’s no reason to block these crucial resources. Doing so can prevent your content from being rendered and, in turn, from being indexed.
Ensure Google Is Indexing JavaScript Content
Once you confirm your pages are rendering properly, ensure they’re being indexed.
You can check this in GSC or on the search engine itself.
To check on Google, use the “site:” command. For example, replace yourdomain.com below with the URL of the page you want to test:
site:yourdomain.com/page-URL/If the page is indexed, you’ll see it show up as a result. Like so:

If you don’t, the page isn’t in Google’s index.
If the page is indexed, check whether a section of JavaScript-generated content is indexed.
Again, use the “site:” command and include a snippet of JS content on the page.
For example:
site:yourdomain.com/page-URL/ "snippet of JS content"You’re checking whether this specific section of JS content has been indexed. If it is, you’ll see it within the snippet.
Like this:

You can also use GSC to see whether JavaScript content is indexed. Again, using the URL Inspection Tool.
This time, rather than testing the live URL, click the “View Crawled Page” button. And check the page’s HTML source code.

Scan the HTML code for snippets of JavaScript content.
If you don’t see your JS content, it could be for several reasons:
- The content cannot be rendered
- The URL cannot be discovered because JS is generating internal links pointing to it in the event of a click
- The page times out while Google is indexing the content
Run a Site Audit
Regularly running audits on your site is a technical SEO best practice.
Semrush Site Audit can crawl JS as Google would. Even if it’s rendered client-side.
To start, enter your domain, and click “Create project.”

Then, choose “Enabled” for JS-rendering in the crawler settings.

After the crawl, you’ll find any issues under the “Issues” tab.

Common JavaScript SEO Issues & How to Avoid Them
Here are some of the most common issues, as well as some JavaScript SEO best practices:
- Blocking .js files in your robots.txt file can prevent Googlebot from crawling these resources. Which means it can’t render and index them. Allow these files to be crawled to avoid this problem.
- Google doesn’t wait long for JavaScript content to render. Your content may not be indexed because of a timeout error.
- Search engines don’t click buttons. Use internal links to help Googlebot discover your site’s pages.
- When lazy loading a page using JavaScript, don’t delay loading content that should be indexed. Primarily focus on images versus text content when setting up lazy loading.
- Google often ignores hashes, so make sure static URLs are generated for your site’s webpages. Ensure your URLs look like this: (yourdomain.com/web-page). And not like this (yourdomain.com/#/web-page) or this (yourdomain.com#web-page).
Take It a Step Further
If you use what you’ve learned about JavaScript SEO, you’ll be well on your way to creating efficient websites that rank well and users love.
Ready to dive deeper?
We recommend reading the following to learn more about JS and technical SEO: