
TF-IDF is a statistical method commonly used in information retrieval and natural language processing.
It’s an important concept for understanding how search engines analyze web content and identify key terms that can be associated with search queries.
Here’s what you need to know about it.
What Is Term Frequency-Inverse Document Frequency (TF-IDF)?
Term frequency-inverse document frequency (TF-IDF) measures the importance of a word to a specific document.
It’s the product of two statistics: term frequency (TF) and inverse document frequency (IDF).
Term Frequency (TF)
Term frequency (TF) can be defined as the relative frequency of a term (t) within a document (d).
It’s calculated by dividing the number of times the term occurs in the document (ft,d) by the total number of terms in the document.
Here’s the formula:
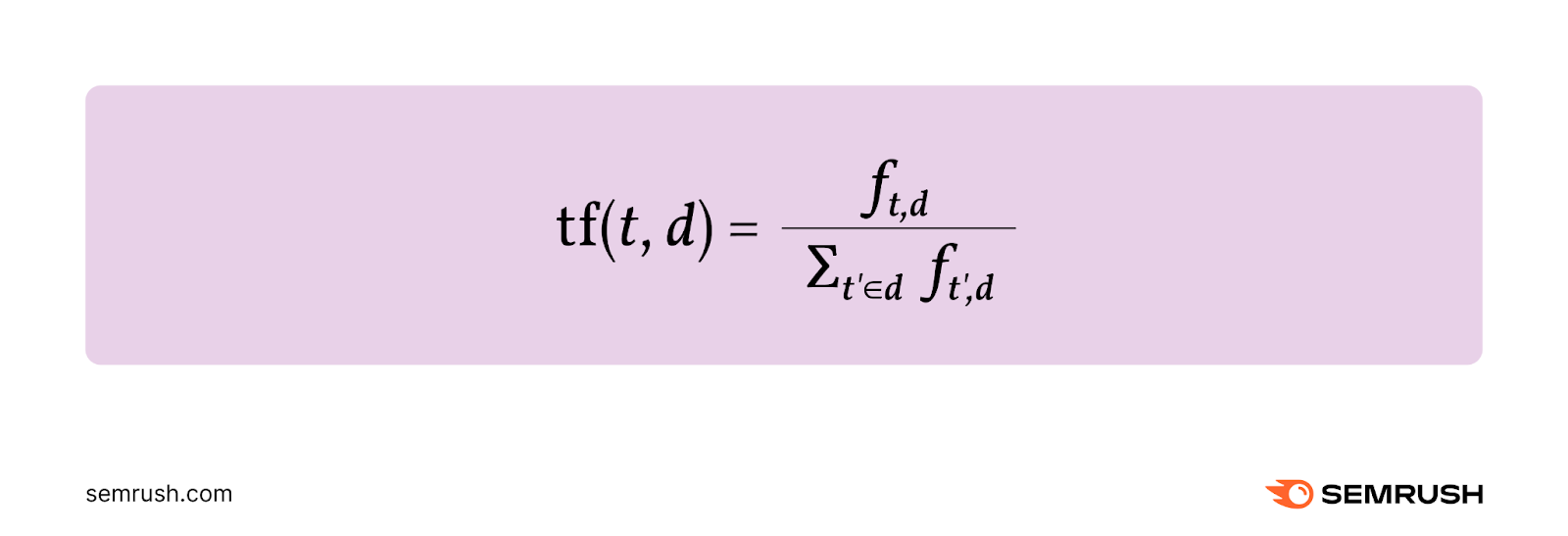

For example, say you have a document containing 10,000 terms. And a specific term appears a total of 25 times in the document.
You’d calculate the term frequency as follows:
TF = 25/10,000 = 0.0025
Inverse Document Frequency (IDF)
Inverse document frequency (IDF) measures the amount of information a term provides.
It’s calculated by dividing the total number of documents (N) by the number of documents that contain the term. Then, taking the logarithm of that quotient.
Here’s the formula:
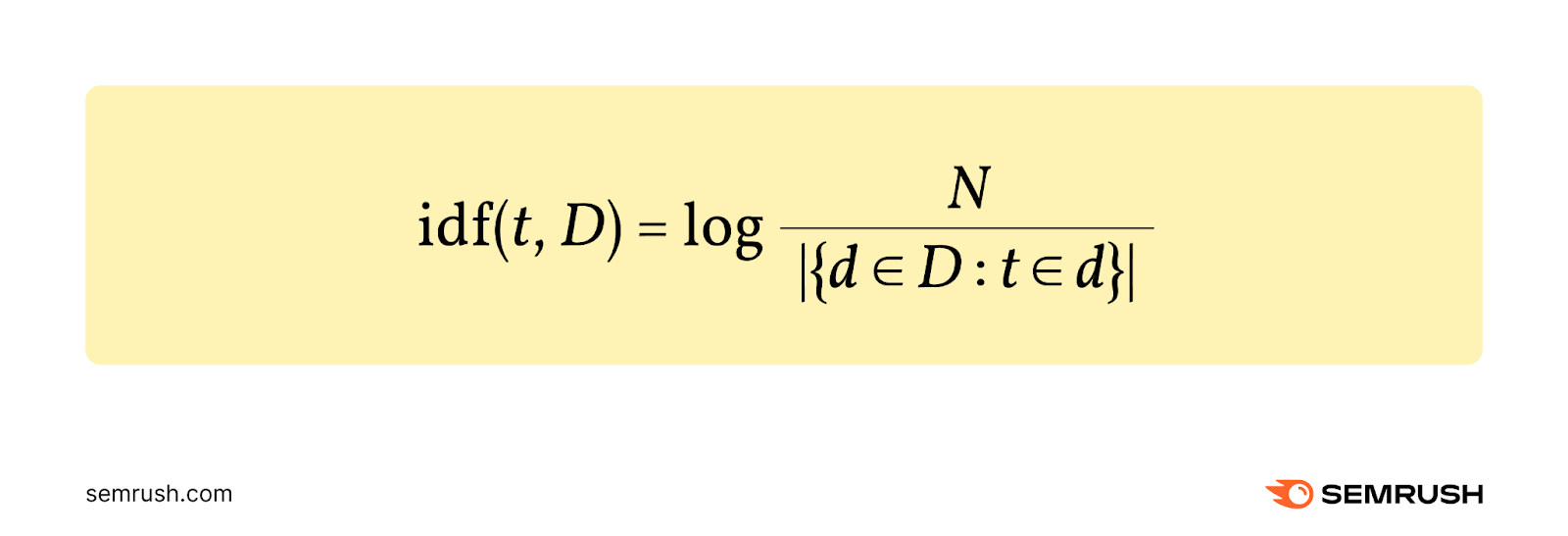
Let's say you have a collection of 10,000 documents (N=10,000), and a term appears in 500 of these documents.
Here’s how you’d calculate the IDF:
IDF = log 10,000/500 = 1.30
TF-IDF Formula
To calculate TF-IDF, we need to multiply the values of TF and IDF:

TF-IDF = 0.00325
The final score shows the relevance of the term, with a higher score denoting higher relevance and a lower score denoting lower relevance.
An Example of How to Calculate TF-IDF
So, how does TF-IDF work in practice?
Simply examining the TF, IDF, and TF-IDF formulas can be a bit overwhelming. Let’s take a look at an actual example.
Let’s say that the term “car” appears 25 times in a document that contains 1,000 words.
We’d calculate the term frequency (TF) as follows:
TF = 25/1,000 = 0.025
Next, let’s say that a collection of related documents contains a total of 15,000 documents.
If 300 documents out of the 15,000 contain the term “car,” we would calculate the inverse document frequency as follows:
IDF = log 15,000/300 = 1.69
Now, we can calculate the TF-IDF score by multiplying these two numbers:
TF-IDF = TF x IDF = 0.025 x 1.69 = 0.04225
How to Use TF-IDF
TF-IDF has a number of applications. It can be used as a weighting factor for:
- Information retrieval: Variations of TF-IDF are used as a weighting factor by search engines to help understand the relevance of a page to a user’s search query
- Text mining: TF-IDF can help quantify what a document is about, which is a central question in text mining
- User modeling: Another application of TF-IDF involves assisting in the creation of models for user behavior and interests, which can then be used by product and content recommendation engines
Use Semrush’s On Page SEO Checker for TF-IDF
Looking to do a bit of TF-IDF analysis for your own website? This is where Semrush’s On Page SEO Checker can help.
You can use it to compare TF-IDF scores between your website content and competing pages.
Here’s how:
Enter your domain on the On Page SEO Checker page and hit the “Get ideas” button.
The tool will then analyze your website. And present you with a report containing a list of ideas for optimizing your website for search engines.
To see TF-IDF scores for a specific page, visit the “Optimization Ideas” tab.
Find your desired page in the list, and click the blue button showing the total number of ideas for that page.
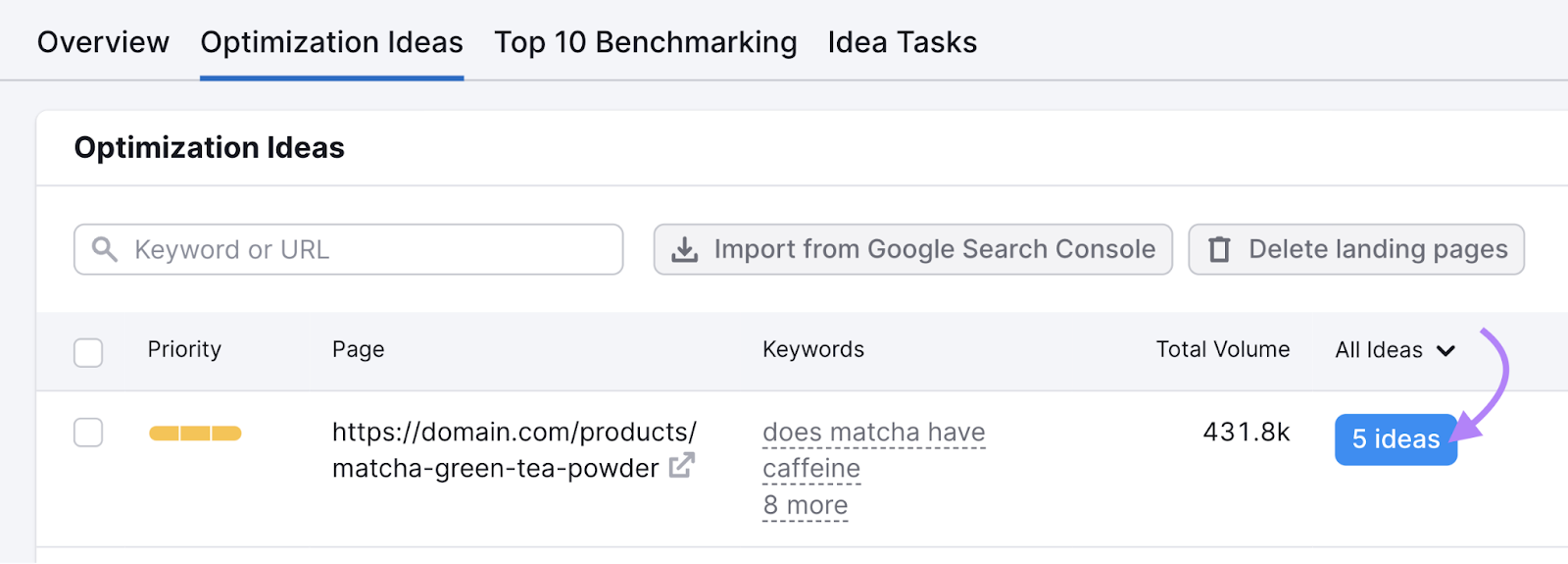
Here, you’ll be presented with a list of ideas for that specific page.
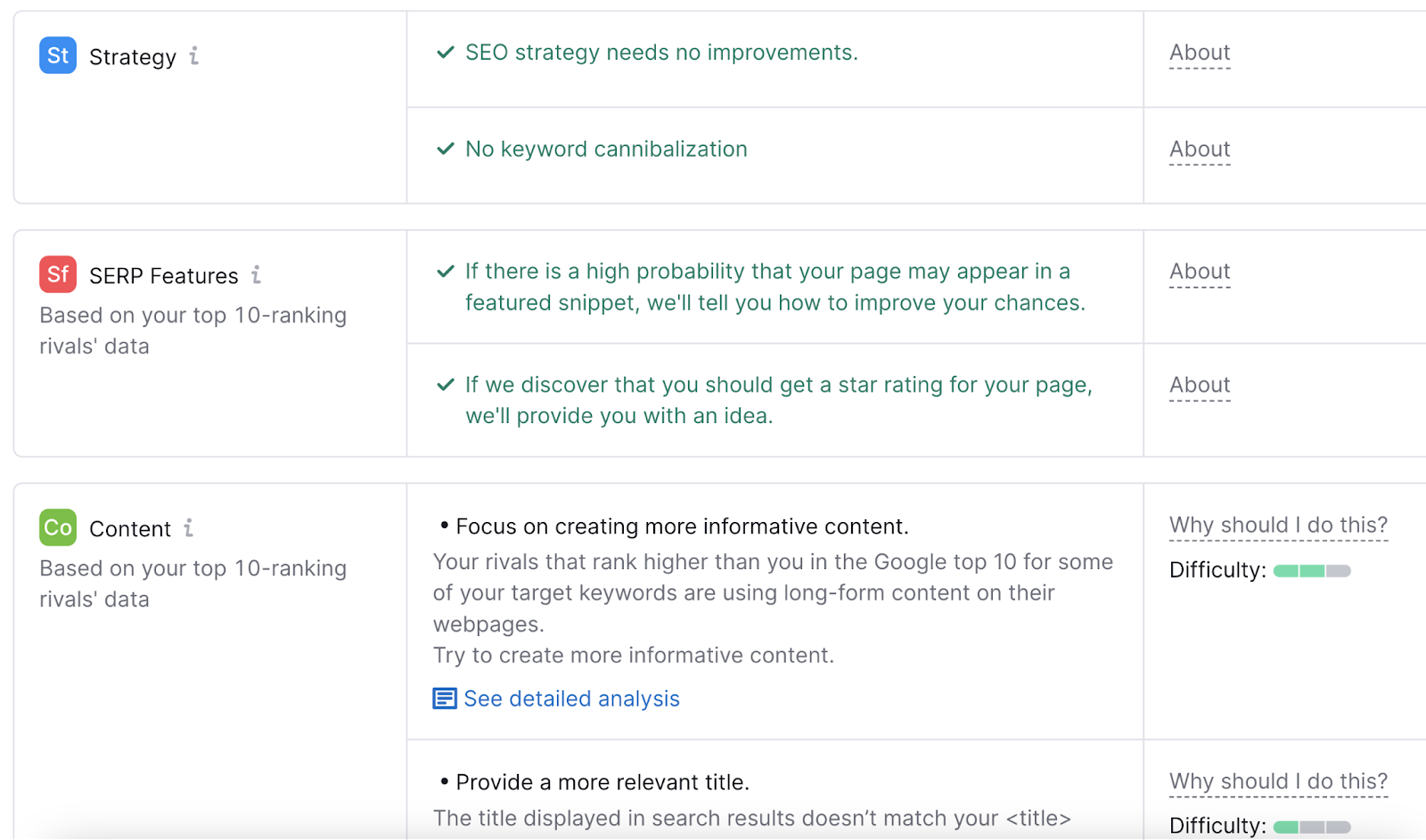
Click on the “See detailed analysis” link under any of the ideas listed in the report.
Go to the “Keyword Usage” tab.
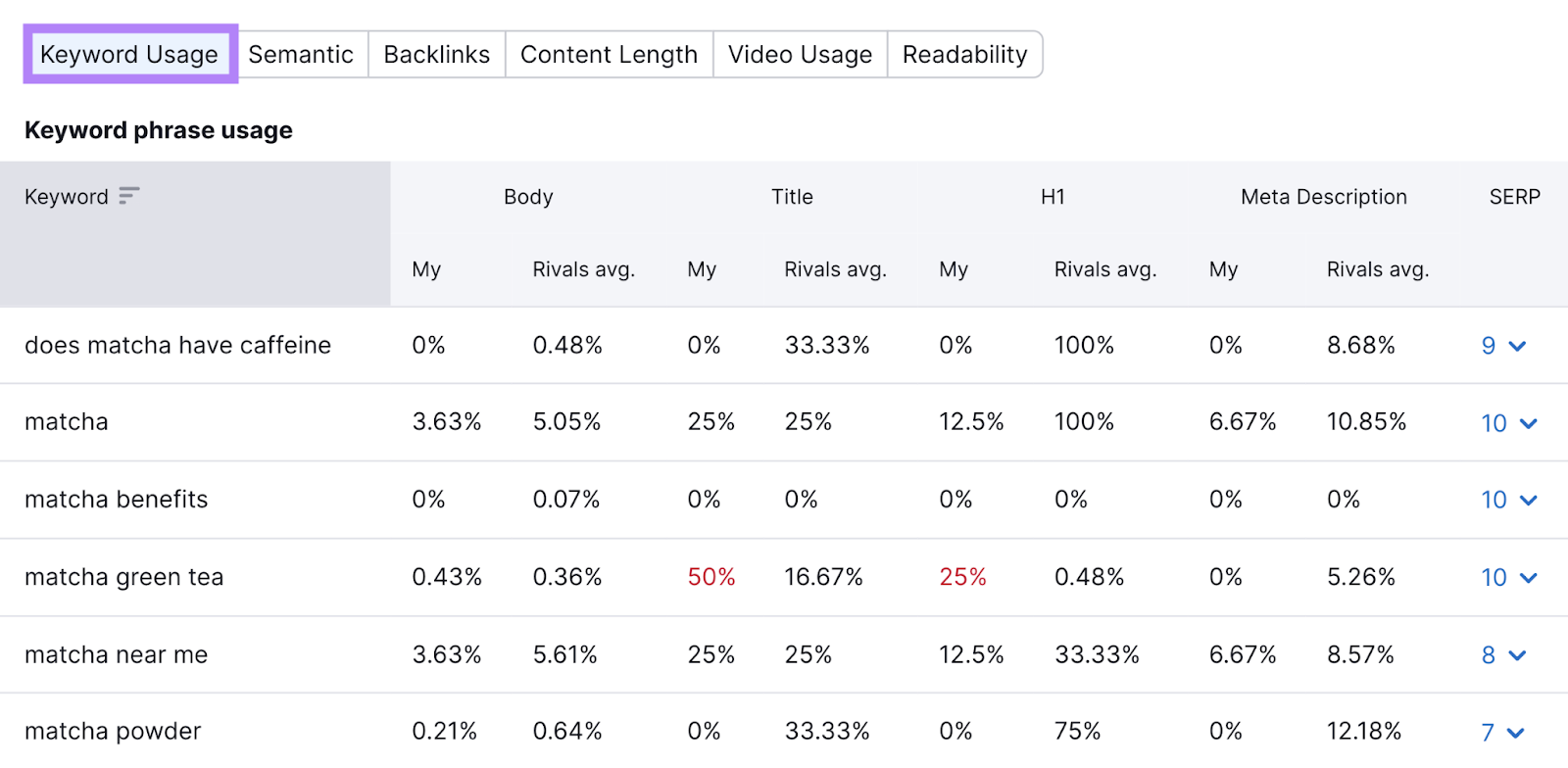
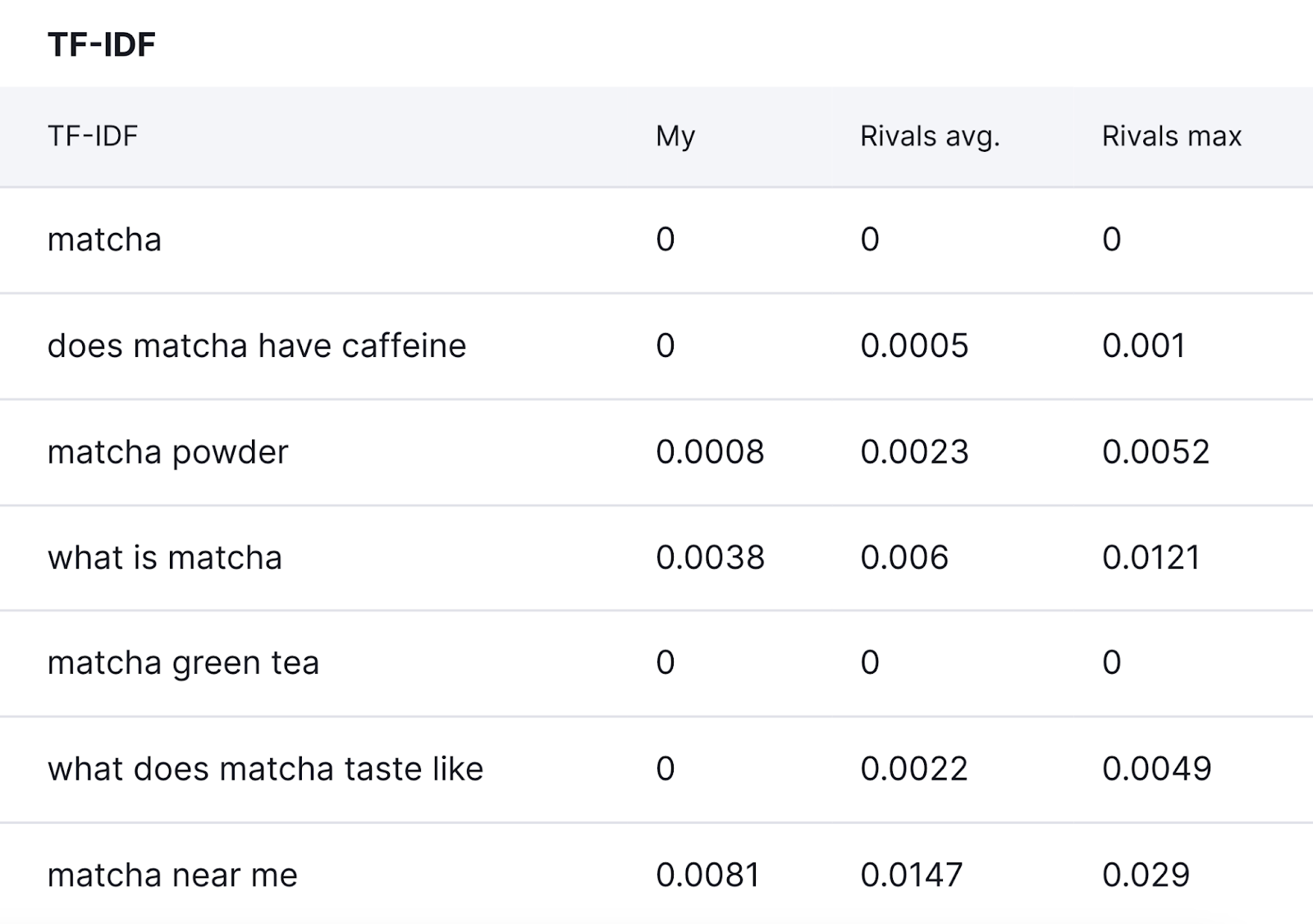
You’ll be able to compare TF-IDF scores in the “TF-IDF” section, as shown below.
Benefits of Using TF-IDF
Here are the main advantages of TF-IDF:
- Easy to calculate: Perhaps the biggest benefit of using TF-IDF is that it’s fairly simple to calculate and can serve as a starting point for more advanced analysis
- Identifies important terms: It can help identify important terms in a document, which is very useful for understanding what a document is about
- Differentiates between common and rare terms: Since TF-IDF looks at both the number of occurrences of a term in a single document—as well as the number of occurrences of the same term in a collection of documents—it helps to differentiate between common and rare terms
- Language-independent: TF-IDF works across all languages and is not limited by the language of a document
- Scalable: It’s capable of handling very big datasets containing a large number of documents
Disadvantages of Using TF-IDF
TF-IDF also comes with its set of limitations:
- Very rare terms can be problematic: IDF scores can be misleadingly high for very rare terms, making them seem more important than they really are
- No understanding of meaning or context: TF-IDF only measures term frequency—it doesn’t understand the meaning behind the terms or the context in which they’re used
- Ignores word order: TF-IDF doesn’t care about word order so it can’t comprehend compound nouns or phrases as single-unit terms
- Difficulties interpreting synonyms and similar words: Since TF-IDF treats each term independently, it can have difficulties recognizing synonyms and similar words, which can lead to misleading scores
The Evolving Role of TF-IDF in AI and Machine Learning
TF-IDF has numerous applications for artificial intelligence (AI) and machine learning algorithms, including information retrieval, text mining, and more.
It keeps evolving alongside AI, with domain-specific TF-IDF models being developed at the moment. These models take into account the characteristics and nuances of specific industries they’re intended for.
Some examples include TF-IDF models aimed at the healthcare industry, which are capable of analyzing clinical notes and medical records to retrieve valuable information for diagnosing and treating diseases.
TF-IDF is now being combined with transformer machine learning models (which learn context by tracking relationships between terms).
It’s also being utilized along with word embeddings.In this approach, terms are mapped to vectors, and the relationships between them are determined based on the distance in vector space.
In other words, these methods improve text analysis and information retrieval.
Stay on Top of TF-IDF with Semrush
You can stay conscious of your content’s TF-IDF scores and compare them with those of your competitors by using Semrush’s On Page SEO Checker.
Apart from showing TF-IDF scores, the On Page SEO Checker can also help you identify dozens of ways to improve your website’s on-page SEO.
And improve your likelihood of ranking your content higher in search engine results.
This post was updated in 2024. Excerpts from the original article by Christina Sanders may remain.