What Is a Meta Robots Tag?
A meta robots tag is an HTML element that tells search engine robots how to crawl, index, and display a page’s content. The meta robots tag goes in the <head> section of the page and can look like:
<meta name="robots" content="noindex">
This example tells search engine crawlers not to index the page. Robots meta tags can control many other crawler behaviors. They’re important for SEO because they let you specify which content should appear in search results.
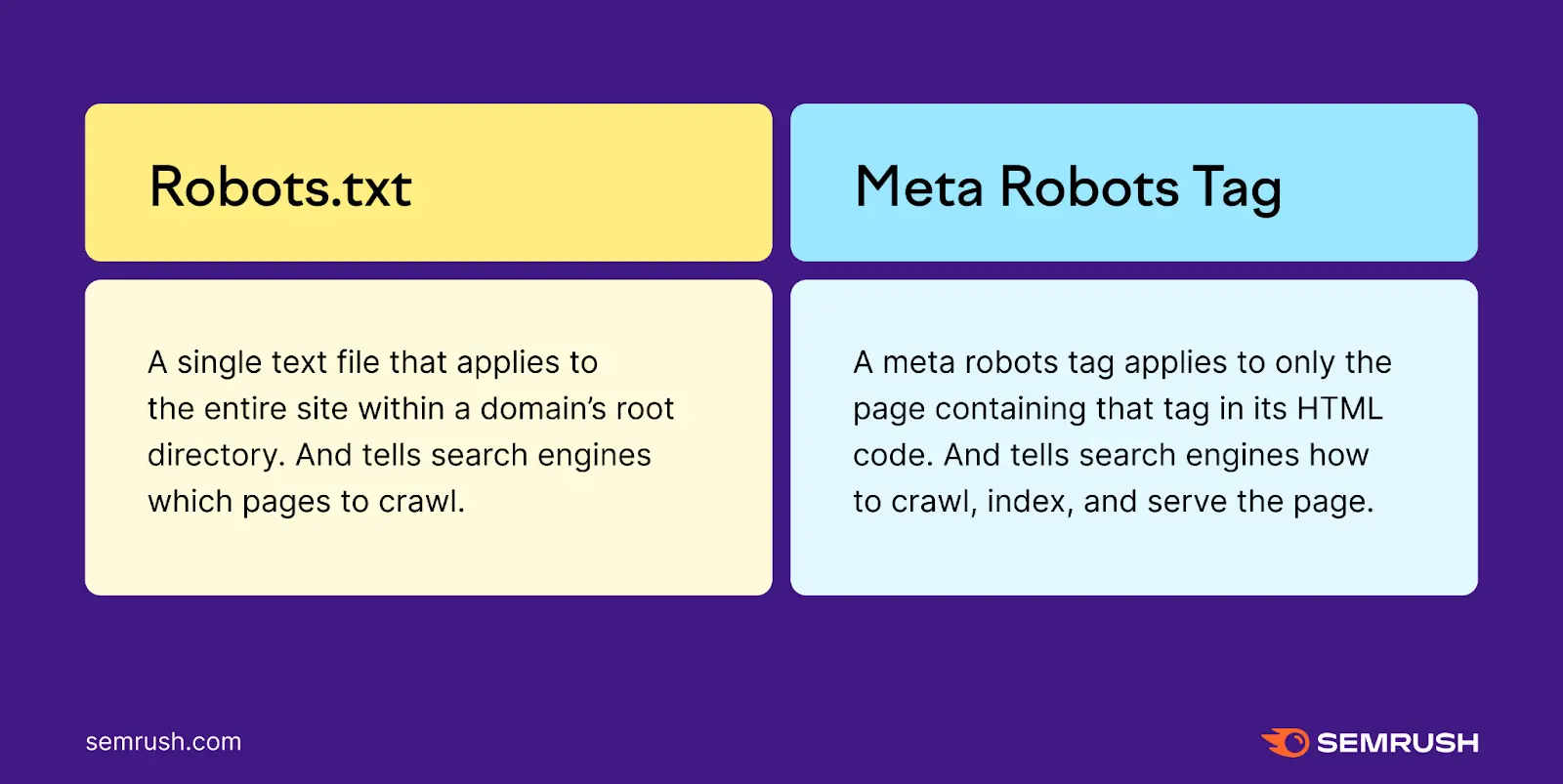
Meta Robots vs. Robots.txt
Meta robots tags and robots.txt files both influence how search engines crawl pages. However, each works differently:
- A robots.txt file is a single text file that applies to the entire site. It instructs search engines which pages to crawl.
- A meta robots tag applies only to the page it appears on. It tells search engines how to index (or not index) that specific page’s content.
What Are Robots Meta Tags Used For?
Robots meta tags help you control how Google and other search engines handle a page’s content. You can specify whether to:
- Include a page in the search results
- Follow the links on the page
- Index images on the page
- Show cached results in search results pages (SERPs)
- Show a snippet of the page in SERPs
Next, this article explains which attributes you can use to instruct search engines. But first, learn why robots meta tags are important and how they affect SEO.
How Do Robots Meta Tags Affect SEO?
Robots meta tags let search engines crawl and index your pages efficiently. This is especially useful for large or frequently updated sites. You may not want every page to rank in search results, such as:
- Staging or development pages
- Confirmation pages, like thank-you pages
- Admin or login pages
- Internal search result pages
- Pages with duplicate content
Combining robots meta tags with other directives (like sitemaps and robots.txt) is helpful for technical SEO. It can prevent crawl and index issues that harm performance.
What Are the Name and Content Specifications for Meta Robots Tags?
Meta robots tags contain two attributes: name and content. Both are required.
Name Attribute
The “name” attribute indicates which crawler the instructions apply to. For example:
name="crawler"
To address all crawlers, set name="robots". This attribute is not case-sensitive, so “robots,” “ROBOTS,” and “Robots” all work.
To target specific search engines, use their crawler names (e.g., Googlebot, Bingbot). Note that not all bots respect meta robots tags, so avoid using them for security.
Content Attribute
The “content” attribute contains instructions for the crawler, such as:
content="instruction"
This attribute is also not case-sensitive. Google supports several “content” values:
Default Content Values
If there is no meta robots tag, crawlers index content and follow links by default. This is the same as adding content="all".
Noindex
<meta name="robots" content="noindex">
Tells crawlers not to index or display the page in search results. Commonly used for cart or checkout pages.
Nofollow
<meta name="robots" content="nofollow">
Tells crawlers not to follow any links on the page. The nofollow attribute is useful if you don’t control the links on a page, such as in user-generated content.
Noarchive
<meta name="robots" content="noarchive">
Prevents Google from showing a cached copy of your page in search results. Useful for time-sensitive or internal documents.
Noimageindex
<meta name="robots" content="noimageindex">
Stops Google from indexing images on the page. Users can still see images on the page itself, so use caution if you want image-based traffic.
Notranslate
<meta name="robots" content="notranslate">
Prevents Google from offering translations of the page. Useful if you don’t want product names or important terms auto-translated.
Nositelinkssearchbox
<meta name="robots" content="nositelinkssearchbox">
Prevents Google from generating a search box for your site in search results.
Nosnippet
<meta name="robots" content="nosnippet">
Prevents Google from showing text or video snippets. Also prevents content from appearing as a direct input for AI Overviews. But it also removes meta descriptions and rich snippets.
You can alternatively prevent only certain sections from showing by using the data-nosnippet attribute:
<p>This text could be shown
<span data-nosnippet>but this part would not be shown</span>.</p>
Max-snippet
<meta name="robots" content="max-snippet:100">
Specifies the maximum character length for text snippets.
- 0 means no snippets.
- -1 means no limit.
Max-image-preview
<meta name="robots" content="max-image-preview:large">
Controls the maximum size of preview images. Values can be “none,” “standard,” or “large.”
Max-video-preview
<meta name="robots" content="max-video-preview:10">
Controls the maximum length of a video snippet in seconds.
- 0 means no video snippets.
- -1 means no limit.
Indexifembedded
<meta name="robots" content="noindex, indexifembedded">
Lets Google index a page’s content if it’s embedded in another page through iframes. This helps media publishers who don’t want direct indexing of media pages, but do want indexing when the media is embedded elsewhere. Not all search engines support this.
Unavailable_after
<meta name="robots" content="unavailable_after: 2024-10-21">
Tells Google to stop showing the page in SERPs after the specified date or time. Use RFC 822, RFC 850, or ISO 8601 formats. This functions like a timed noindex.
Combining Robots Meta Tag Rules
You can combine rules in two ways:
Multiple Values in One “content” Attribute
<meta name="robots" content="noindex, nofollow">
- This example tells crawlers not to index the page or follow links. You can also use content="none" to combine noindex and nofollow together, but some search engines (like Bing) do not support this keyword.
If conflicting directives appear, Google applies the most restrictive one.
Multiple Robots Meta Elements
<meta name="robots" content="nofollow">
<meta name="YandexBot" content="noindex">
- This example tells all crawlers to avoid following links, but also instructs Yandex to not index the page at all.
Search Engine Support for Meta Robots Tags
| Value | | Bing | Yandex |
| noindex | Y | Y | Y |
| noimageindex | Y | N | N |
| nofollow | Y | N | Y |
| noarchive | Y | Y | Y |
| nocache | N | Y | N |
| nosnippet | Y | Y | N |
| nositelinkssearchbox | Y | N | N |
| notranslate | Y | N | N |
| max-snippet | Y | Y | N |
| max-video-preview | Y | Y | N |
| max-image-preview | Y | Y | N |
| indexifembedded | Y | N | N |
| unavailable_after | Y | N | N |
How to Implement Robots Meta Tags
Adding Robots Meta Tags to Your HTML Code
Place meta robots tags in the <head> section of the page:
<meta name="robots" content="noindex, nofollow">
Implementing Robots Meta Tags in WordPress
If you use Yoast SEO:
- In the page editor, open the “Advanced” tab.

- Set “Allow search engines to show this page in search results?” to “No” for noindex.

- Set “Should search engines follow links on this page?” to “No” for nofollow.

- For other directives, use the “Meta robots advanced” field.

If you use Rank Math:
- Go to the “Advanced” tab in the meta box.
- Choose the directives from the provided checkboxes or fields.

Adding Robots Meta Tags in Shopify
Edit the <head> section of your theme.liquid layout file.

For a specific page:
{% if handle contains 'page-name' %}
<meta name="robots" content="noindex">
{% endif %}
Use separate entries for different pages. Edit theme files carefully or consult a developer.
Implementing Robots Meta Tags in Wix
- Open your Wix dashboard and click “Edit Site.”

- Click “Pages & Menu.”
- Next to the desired page, click “...” → “SEO basics.”

- Under “Advanced SEO,” open “Robots meta tag.”

- Select the relevant robots meta tags via checkboxes. For directives like notranslate or nositelinkssearchbox, click “Additional tags” → “Add New Tags.”
Now, you can paste your meta tag in HTML format.

What Is the X-Robots-Tag?
An x-robots-tag instructs crawlers how to index non-HTML resources (such as PDFs or images). It goes in the HTTP header response:
makefile
X-Robots-Tag: noindex, nofollow
You can use the same rules as meta robots tags. However, you must edit server configuration files like .htaccess on Apache or .conf on Nginx.
How to Implement X-Robots-Tags
Using X-Robots-Tag on an Apache Server
In your site’s .htaccess or httpd.conf, add:
arduino
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex, nofollow"
</Files>
This instructs crawlers not to index or follow links on any PDF across the entire site.
Using X-Robots-Tag on an Nginx Server
In your site’s .conf file, add:
ruby
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
This applies noindex, nofollow to all PDFs on the site.
Common Meta Robots Tag Mistakes to Avoid
- Using Meta Robots on a Page Blocked by Robots.txt: If a page is disallowed in robots.txt, search engine bots will never see the meta robots tag on that page.
- Adding Robots Directives to Robots.txt: Google no longer supports noindex rules in robots.txt. Use meta robots tags or x-robots-tags instead.
- Removing Pages with Noindex from Sitemaps Too Early: Keep the page in your sitemap until it’s deindexed. Otherwise, deindexing may be delayed.
- Forgetting to Remove Staging ‘Noindex’: When you move a site from staging to production, remove any noindex directives to avoid blocking the entire live site from indexing.
How to Check Your Website for Meta Robots Tag Issues
One of the best ways to check your website for meta robots tag issues is to use Semrush’s Site Audit tool:
- Enter your domain and click “Start Audit.”

- Adjust settings if needed, then run the audit.

- In the “Issues” tab, search for “blocked from crawling” or other errors related to meta robots tags.

- Review “Why and how to fix it” for each issue.
- Correct these issues to improve crawlability.
FAQs
When Should You Use the Robots Meta Tag vs. X-Robots-Tag?
Use the robots meta tag for HTML pages and the x-robots-tag for non-HTML resources. You can technically use x-robots-tag for HTML pages, but meta tags are simpler. X-robots-tags also allow bulk rules for file types like PDF.
Do You Need to Use Both Meta Robots Tag and X-Robots-Tag?
No. One is enough. Using both does not increase the likelihood that crawlers will follow your directives.
What Is the Easiest Way to Implement Robots Meta Tags?
A plugin is typically the easiest method. It avoids manual code edits. The best plugin depends on your content management system (CMS).
Use Meta Robots Tags Correctly to Avoid Indexing Issues
Robots meta tags ensure that important content is indexed. Without proper indexing, your pages will not drive any organic traffic. Directives like noindex and nofollow are crucial for controlling your site’s search presence. Check that you have implemented them properly with Semrush Site Audit.