
What Is Crawlability?
The crawlability of a webpage refers to how easily search engines (like Google) can discover the page.
Google discovers webpages through a process called crawling. It uses computer programs called web crawlers (also called bots or spiders). These programs follow links between pages to discover new or updated pages.
Indexing usually follows crawling.
What Is Indexability?
The indexability of a webpage means search engines (like Google) are able to add the page to their index.
The process of adding a webpage to an index is called indexing. It means Google analyzes the page and its content and adds it to a database of billions of pages (called the Google index).
How Do Crawlability and Indexability Affect SEO?
Both crawlability and indexability are crucial for SEO.
Here's a simple illustration showing how Google works:
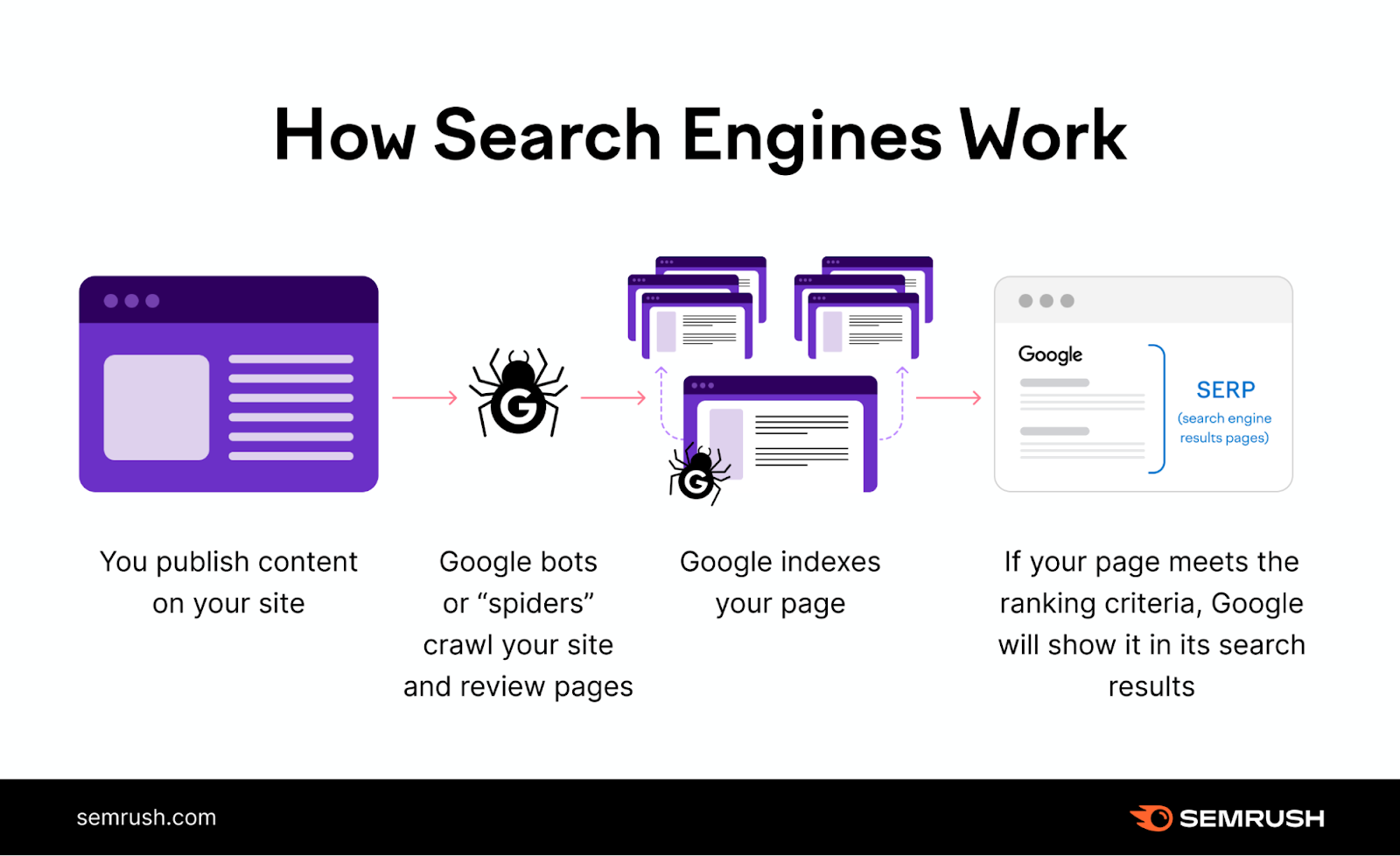
First, Google crawls the page. Then it indexes it. Only then can it rank the page for relevant search queries.
In other words: Without first being crawled and indexed, the page will not be ranked by Google. No rankings = no search traffic.
Matt Cutts, Google’s former head of web spam, explains the process in this video:

It's no surprise that an important part of SEO is making sure your website's pages are crawlable and indexable.
But how do you do that?
Start by conducting a technical SEO audit of your website.
Use Semrush's Site Audit tool to help you discover crawlability and indexability issues. (We'll address this in detail later in this post.)
What Affects Crawlability and Indexability?
Internal Links
Internal links have a direct impact on the crawlability and indexability of your website.
Remember—search engines use bots to crawl and discover webpages. Internal links act as a roadmap, guiding the bots from one page to another within your website.

Well-placed internal links make it easier for search engine bots to find all of your website's pages.
So, ensure every page on your site is linked from somewhere else within your website.
Start by including a navigation menu, footer links, and contextual links within your content.
If you’re in the early stages of website development, creating a logical site structure can also help you set up a strong internal linking foundation.
A logical site structure organizes your website into categories. Then those categories link out to individual pages on your site.
Like so:
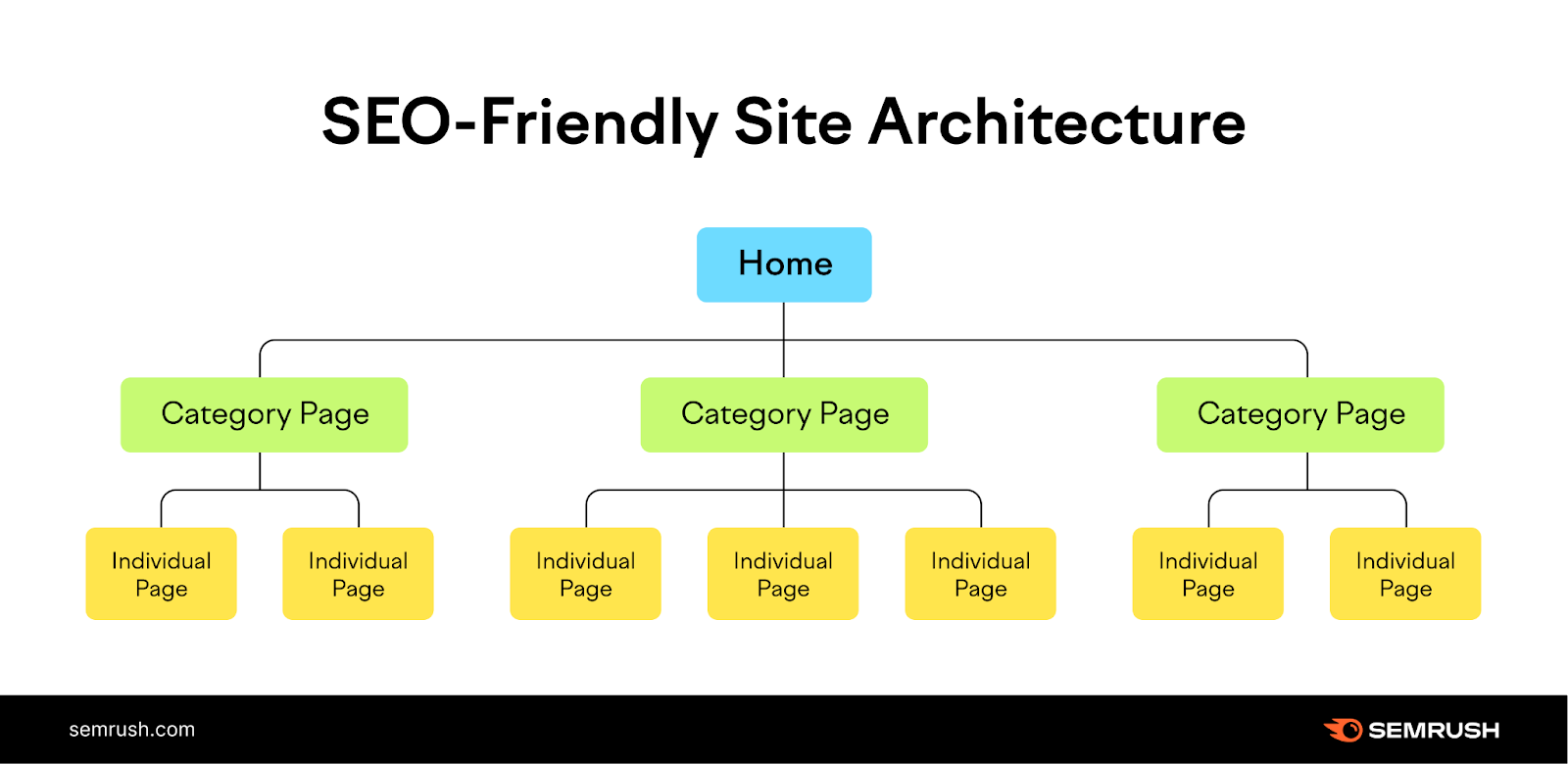
The homepage connects to pages for each category. Then, pages for each category connect to specific subpages on the site.
By adapting this structure, you'll build a solid foundation for search engines to easily navigate and index your content.
Robots.txt
Robots.txt is like a bouncer at the entrance of a party.
It's a file on your website that tells search engine bots which pages they can access.
Here’s a sample robots.txt file:
User-agent: *
Allow:/blog/
Disallow:/blog/admin/
Let’s understand each component of this file.
- User-agent: *: This line specifies that the rules apply to all search engine bots
- Allow: /blog/: This directive allows search engine bots to crawl pages within the "/blog/" directory. In other words, all the blog posts are allowed to be crawled
- Disallow: /blog/admin/: This directive tells search engine bots not to crawl the administrative area of the blog
When search engines send their bots to explore your website, they first check the robots.txt file to check for restrictions.
Be careful not to accidentally block important pages you want search engines to find. Such as your blog posts and regular website pages.
Also, although robots.txt controls crawl accessibility, it doesn't directly impact the indexability of your website.
Search engines can still discover and index pages that are linked from other websites, even if those pages are blocked in the robots.txt file.
To ensure certain pages, such as pay-per-click (PPC) landing pages and “thank you” pages, are not indexed, implement a "noindex" tag.
Read our guide to meta robots tag to learn about this tag and how to implement it.
XML Sitemap
Your XML sitemap plays a crucial role in improving the crawlability and indexability of your website.
It shows search engine bots all the important pages on your website that you want crawled and indexed.
It's like giving them a treasure map to discover your content more easily.
So, include all your essential pages in your sitemap. Including ones that might be hard to find through regular navigation.
This ensures search engine bots can crawl and index your site efficiently.
Content Quality
Content quality impacts how search engines crawl and index your website.
Search engine bots love high-quality content. When your content is well-written, informative, and relevant to users, it can attract more attention from search engines.
Search engines want to deliver the best results to their users. So they prioritize crawling and indexing pages with top-notch content.
Focus on creating original, valuable, and well-written content.
Use proper formatting, clear headings, and organized structure to make it easy for search engine bots to crawl and understand your content.
For more advice on creating top-notch content, check out our guide to quality content.
Technical Issues
Technical issues can prevent search engine bots from effectively crawling and indexing your website.
If your website has slow page load times, broken links, or redirect loops, it can hinder bots' ability to navigate your website.
Technical issues can also prevent search engines from properly indexing your webpages.
For instance, if your website has duplicate content issues or is using canonical tags improperly, search engines may struggle to understand which version of a page to index and rank.
Issues like these are detrimental to your website’s search engine visibility. Identify and fix these issues as soon as possible.
How to Find Crawlability and Indexability Issues
Use Semrush’s Site Audit tool to find technical issues that affect your website’s crawlability and indexability.
The tool can help you find and fix problems like:
- Duplicate content
- Redirect loops
- Broken internal links
- Server-side errors
And more.
To start, input your website URL and click “Start Audit.”

Next, configure your audit settings. Once done, click “Start Site Audit.”

The tool will begin auditing your website for technical issues. After completion, it will show an overview of your website’s technical health with a “Site Health” metric.

This measures the overall technical health of your website on a scale from 0 to 100.
To see issues related to crawlability and indexability, navigate to “Crawlability” and click “View details.”

This will open a detailed report that highlights issues affecting your website’s crawlability and indexability.

Click on the horizontal bar graph next to each issue item. The tool will show you all the affected pages.

If you’re unsure of how to fix a particular issue, click the “Why and how to fix it” link.
You’ll see a short description of the issue and advice on how to fix it.

By addressing each issue promptly and maintaining a technically sound website, you'll improve crawlability, help ensure proper indexation, and increase your chances of ranking higher.
How to Improve Crawlability and Indexability
Submit Sitemap to Google
Submitting your sitemap file to Google helps get your pages crawled and indexed.
If you don’t already have a sitemap, create one using a sitemap generator tool like XML Sitemaps.
Open the tool, enter your website URL, and click “Start.”

The tool will automatically generate a sitemap for you.
Download your sitemap and upload it to the root directory of your site.
For example, if your site is www.example.com, then your sitemap should be located at www.example.com/sitemap.xml.
Once your sitemap is live, submit it to Google via your Google Search Console (GSC) account.
Don’t have GSC set up? Read our guide to Google Search Console to get started.
After activation, navigate to “Sitemaps” from the sidebar. Enter your sitemap URL and click “Submit.”

This improves the crawlability and indexation of your website.
Strengthen Internal Links
The crawlability and indexability of a website also lies within its internal linking structure.
Fix issues related to internal links, such as broken internal links and orphaned pages (i.e., pages with no internal links), and strengthen your internal linking structure.
Use Semrush’s Site Audit tool for this purpose.
Go to the “Issues” tab and search for “broken.” The tool will display any broken internal links on your site.

Click “XXX internal links are broken” to view a list of broken internal links.

To address the broken links, you can restore the broken page. Or implement a 301 redirect to the relevant, alternative page on your website
Now to find orphan pages, go back to the issues tab and search for “orphan.”

The tool will show whether your site has any orphan pages. Address this issue by creating internal links that point to those pages.
Regularly Update and Add New Content
Regularly updating and adding new content is highly beneficial for your website’s crawlability and indexability.
Search engines love fresh content. When you regularly update and add new content, it signals that your website is active.
This can encourage search engine bots to crawl your site more frequently, ensuring they capture the latest updates.
Aim to update your website with new content at regular intervals, if possible.
Whether publishing new blog posts or updating existing ones, this helps search engine bots stay engaged with your site and keep your content fresh in their index.
Avoid Duplicate Content
Avoiding duplicate content is essential for improving the crawlability and indexability of your website.
Duplicate content can confuse search engine bots and waste crawling resources.
When identical or very similar content exists on multiple pages of your site, search engines may struggle to determine which version to crawl and index.
So ensure each page on your website has unique content. Avoid copying and pasting content from other sources, and don't duplicate your own content across multiple pages.
Use Semrush’s Site Audit tool to check your site for duplicate content.
In the “Issues” tab, search for “duplicate content.”

If you find duplicate pages, consider consolidating them into a single page. And redirect the duplicate pages to the consolidated one.
Or you could use canonical tags. The canonical tag specifies the preferred page that search engines should consider for indexing.
Tools for Optimizing Crawlability & Indexability
Log File Analyzer
Semrush’s Log File Analyzer can show you how Google’s search engine bot (Googlebot) crawls your site. And help you spot any errors it might encounter in the process.

Start by uploading the access log file of your website and wait while the tool analyzes your file.
An access log file contains a list of all requests that bots and users have sent to your site. Read our manual on where to find the access log file to get started.
Google Search Console
Google Search Console is a free tool from Google that lets you monitor the indexation status of your website.

See whether all your website pages are indexed. And identify reasons why some pages aren’t.

Site Audit
Site Audit tool is your closest ally when it comes to optimizing your site for crawlability and indexability.
The tool reports on a variety of issues, including many that affect a website’s crawlability and indexability.

Make Crawlability and Indexability Your Priority
The first step of optimizing your site for search engines is ensuring it’s crawable and indexable.
If it isn’t, your pages won’t show up in search results. And you won’t receive organic traffic.
The Site Audit tool and Log File Analyzer can help you find and fix issues relating to crawlability and indexation.
Sign up for free.