
In this article, I outline a method to identify elements of duplicate content to improve the quality and focus of your listing pages. This is imperative for enhanced Google ranking, resulting in potential customers speedily finding what they want, and sales conversions. This process encompasses empty and low-quality taxonomies, such as product listing pages, blog categories, and tags.
E-commerce businesses often have multiple products, categories, and sub-categories, many of which do not add value. It is preferable to have a smaller number of targeted pages which rank for the relevant query, thereby enabling potential customers to find your products, and trust you are a reliable merchant. Below is an example of a store where a category page contains only one product instead of a range of oral hygiene stock.
Searching customers are provided a limited choice and are likely to search elsewhere.
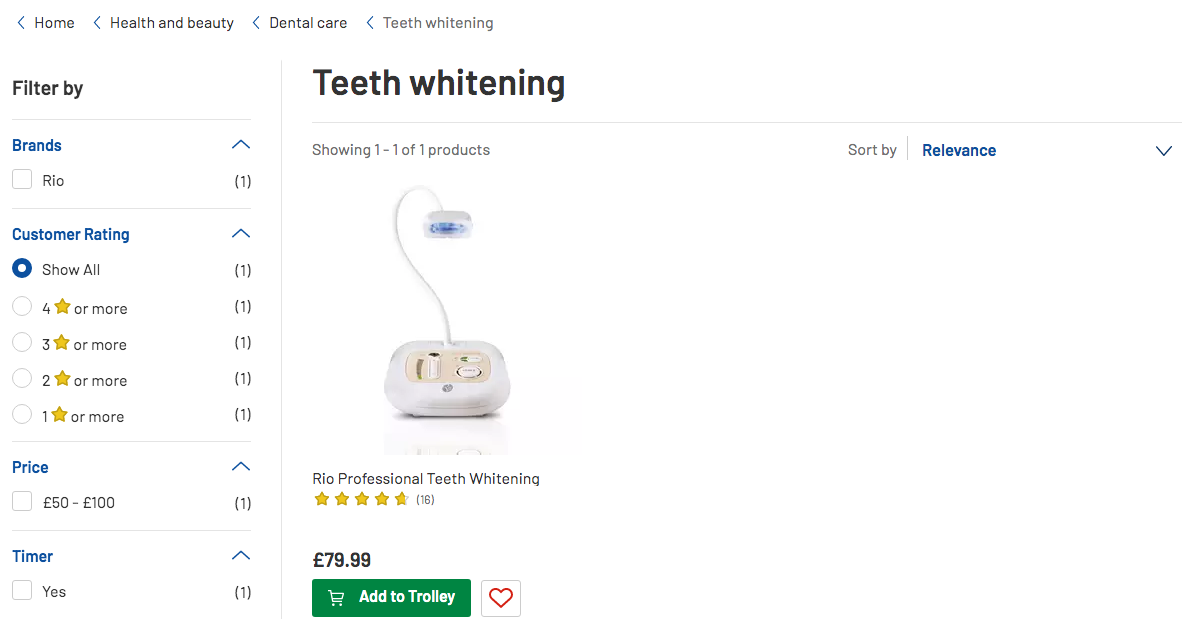 https://www.argos.co.uk/browse/health-and-beauty/dental-care/teeth-whitening/c:29234/
https://www.argos.co.uk/browse/health-and-beauty/dental-care/teeth-whitening/c:29234/
The same applies to blog websites with drastic outcomes. A publisher can create many articles a month with different areas of interest. However, low-value pages with limited content will struggle to rank for terms that potential audiences are searching for and therefore will not attract leads. Below is an example with just two posts. To make matters worse, the same articles are assigned numerous taxonomies resulting in potential duplication.
 https://contentmarketinginstitute.com/tertiary-category/branded-content/
https://contentmarketinginstitute.com/tertiary-category/branded-content/
As you can see, both the e-commerce listing page and archive page contain little content, and that doesn't help anyone. These examples show why you should review your site and ensure you don’t have something similar.
Duplication is Easy
If you have an online business or blog website, generating duplicate or low-value pages is easy; this is especially true if your website is not audited often. Therefore, when publishing a post or product on your site, I recommend this simple check-list below:
- How many categories did you assign to your new post/product?
- How many tags did you add to your post/product?
- Did you check the spelling of your tags? Did you keep them consistent, with singular/plural, hyphen if multiple words, etc.?
- Did you train your editors and e-commerce managers?
- Do you have a solid taxonomy strategy?
- Did you perform solid keyword research?
Many of the website sites I have audited didn’t do this. That is why in this article, I delineate a method which will help you find archive or listing pages with little or no content, be it posts or products, and define what action is required to resolve this.
Duplicates Can Be Automatically Generated Easily
It is really easy to unconsciously generate duplicate and low-quality pages, especially with blogging platforms like WordPress, where assigning a category or a tag to a post is a one-click action. I commonly find auto-generated duplicates while auditing web websites. Left alone, they can be harmful.
A blog post with multiple and similar tags, as well as categories, automatically generates an archive for each of them. Auto-generated pages also occur when the amount of content is large or the site is a few years old.
Consequences of unplanned duplicate taxonomies include:
- Generate archives with the same content, and consequently duplicate pages
- Lack of optimization of webpages
- Pages that contain only little content
- Providing poor user experience
- Issue potential content cannibalization problems
- Forcing Google (and other search engines) to choose pages on other websites
The result of this is less organic traffic turning into leads and potential sales.
When publishing new content, you should organize your site to provide the best topic-relevant information possible. Each page you create, or automatically generate, should have its own unique goal.
There are multiple ways to do it this, which is outside the scope of this article. Useful examples include topic clusters, website architecture, site architecture, internal linking, creating silos, architecture issues, amongst others.
What Does It Really Mean?
Using a digital marketing blog as an example, with a focus on 3 widely used tags: ‘Digital Marketing’, ‘Google Ads’ and ‘Social Media’.
The following is an example of what you can find in your tags dashboard:
Digital Marketing
domain.com/tag/digitalmarketing
domain.com/tag/digital-marketing
Google Ads
domain.com/tag/googleads
domain.com/tag/google-ads
domain.com/tag/adwords
domain.com/tag/ad-words
domain.com/tag/googleadwords
domain.com/tag/google-adwords
Social Media
domain.com/tag/social
domain.com/tag/socialmedia
domain.com/tag/social-media
domain.com/tag/socialmediamarketing
domain.com/tag/social-media-marketing
Each tag page contains little content, gets low-level traffic, doesn’t provide much value for your readers, and generates content cannibalization issues.
Audit With Your Strategy In Mind
It is not uncommon for a website with 1,000 posts to have a few thousand taxonomy pages.
According to the scale of your website, you should consider potential crawl budget issues involved. Your goal is to ensure Google has a clear idea of what each page is about, without making its algorithms decide between multiple pages. A content strategy is essential, and your website should be organized with new posts created after solid keyword research.
While undertaking an audit of your website, asking the questions listed below are a starting point:
- Are archives supported by keyword research?
- What is their goal?
- Are archive pages customized or do they provide just a list of titles?
Please be mindful that renaming, merging, or deleting taxonomy pages can affect the site structure. This can also impact upon content and technical elements, and generate broken pages or internal redirects.
From a technical standpoint changing how posts are assigned to taxonomies reduces the number of URLs, and generates broken pages due to the decrease of the pagination sequence — this is to be avoided.
So, how do you deal with your taxonomies? Should you 301 redirect them? Should you remove them from the Google index? What about the crawl budget?
From a content and business point of view, do the archive pages provide any value? Do they get backlinks? Are they generating conversions or traffic? Is the site-wide duplicate content you found with the SEO Audit mostly related to archive pages? These questions should be considered when making a decision because every action can impact on other elements.
Even though I strongly believe in content pruning, each choice should be part of a larger strategy.
The Steps To Take
How do you identify low-value archive pages, provide relevant insights to the decision-makers, and take action?
SEMrush provides an insight of duplicate pages, which is the first step in this process.
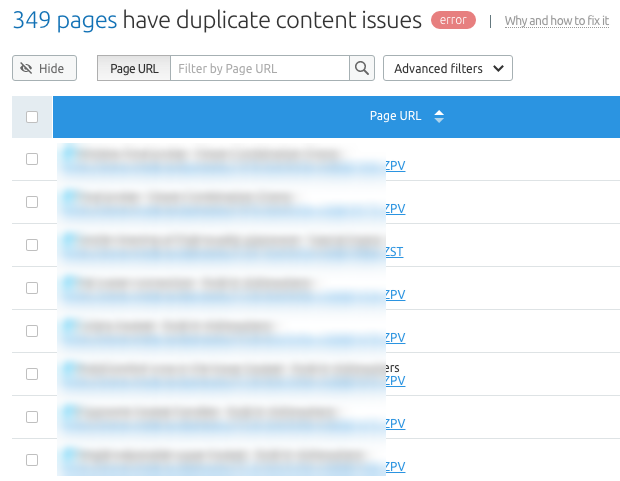 SEMrush Site Audit tool
SEMrush Site Audit tool
To investigate deeper, you can collect more data by identifying common patterns, fingerprints, and HTML elements that can enhance your understanding of the issue.
I advise using a language called XPath, that helps to select values, variables, and locations of specific elements within an XML document. If you are not familiar with this language, I recommend reading the Builtvisible’s SEO’s guide to XPath, to find out how it can be useful in different contexts.
Then use a tool that crawls your website and extracts the selected elements. My favourite is Screaming Frog’s web scraping tool.
Let's see now how we can identify these elements, configure Screaming Frog, and extract the information you need to make the right decisions.
1) Identify Common Elements
To start with, find fingerprints and extract them.
These elements are HTML tags, resources, and other patterns that allow you to recognize the fingerprints in specific areas of every page you check. This enables you to collect these elements and find anomalies or common patterns which can be improved.
Include and Exclude URLs
Because you don't want to be overwhelmed with too much data, crawl only URLs that match with the pages that contain the fingerprints you identified. Doing so determines the structure of the page and defines what to crawl and what not.
Folders, words, and other patterns are common elements that should be included. Below I have listed a few examples:
domain.com/element/page
domain.com/tag/post
domain.com/category/product
domain.com/product-category/product
Exclusion is also a key aspect of the crawl. In this example, the pagination sequences are not of interest. In fact, if the archive is paginated the minimum amount of posts (or products) has been already reached. And you also don't want to crawl your whole website, as it can consume resources, take time, and collect too much data.
Pages to exclude can include patterns like:
/page/
?page
which means that the archive has multiple pages.
H1 or Title Tag
These are elements that identify the taxonomy name (or title) and should be unique within the pagination sequence.
As you are performing an audit, you should take care to fix any other potential issues you stumble upon. So, if you can not find the H1 heading, this is an issue you can quickly fix, as the H1 should define the main keyword/topic of the page.
Article Titles/Product Names
The title of the posts (or the name of the products) is the main unique element that identifies the listing within the archive. Take note of this component to build your list of fingerprints.
Number of Articles On the Page
This element counts the number of articles (or products) the archive page includes. This is a key aspect of the work because it gives you an easy overview of the categories that need to be reviewed, as they lack in content or products.
2) Find And Translate HTML Fingerprints In XPath Queries
Next, you should patiently inspect the above-mentioned elements and take note of the HTML source code.
You can use Google Chrome DevTools or Scrape Similar Chrome Extension. As previously mentioned, the SEO’s guide to XPath helps you to spot all the elements, as well as this cheatsheet.
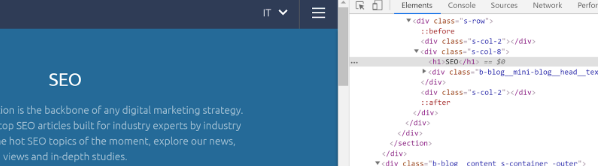 Google Chrome DevTools
Google Chrome DevTools
 Scrape Similar Chrome Extension
Scrape Similar Chrome Extension
Examples:
To convert theory into practice, I have audited three websites for you, identified the above-mentioned fingerprints, selected the elements within the HTML source code, and turned them in XPath queries.
With these examples, you will be able to see if a category page lacks content, with only a few posts assigned (Content Marketing Institute and SEMrush blog), and if product listing pages contain few products (Argos).
After you look at each element and their XPath query, you can configure Screaming Frog. Below are the elements for the three examples:
Content Marketing Institute - https://contentmarketinginstitute.com
Title tag: /html/head/title
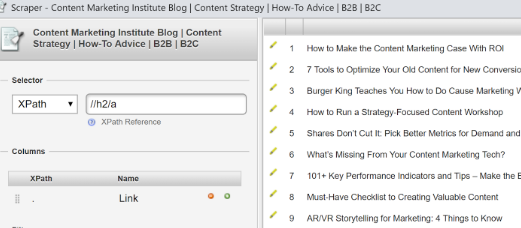
H2 tag with link: //h2/a
Number of articles per page: count(//div[@class='posted'])
Included URLs blog/category: https://contentmarketinginstitute.com/.*category/.*
Excluded URLs /page/: https://contentmarketinginstitute.com/.*/page/.*
Argos UK - https://www.argos.co.uk (Health and Beauty)
H1 tag: //h1[@class='search-title__term']
Article relevant class id: //*[@class='ac-product-name ac-product-card__name']
Number of products per page: count(//div[@class='ac-product-name ac-product-card__name'])
Included URLs browse/health-and-beauty/: https://www.argos.co.uk/browse/health-and-beauty/.*
Excluded URLs /page:X: .*/page.*
SEMrush blog - https://www.semrush.com/blog/
H1 tag: //h1
H2 tag with link: //h2/a
Number of articles per page: count(//div[@class='s-col-12 b-blog__snippet__head'])
Included URLs blog/category: https://www.semrush.com/blog/category/.*
Excluded URLs /page/: https://www.semrush.com/blog/.*\?page.*
3) Configure Screaming Frog
It's now time to configure Screaming Frog.
Go to Configuration > Custom > Extraction and configure the XPath elements.
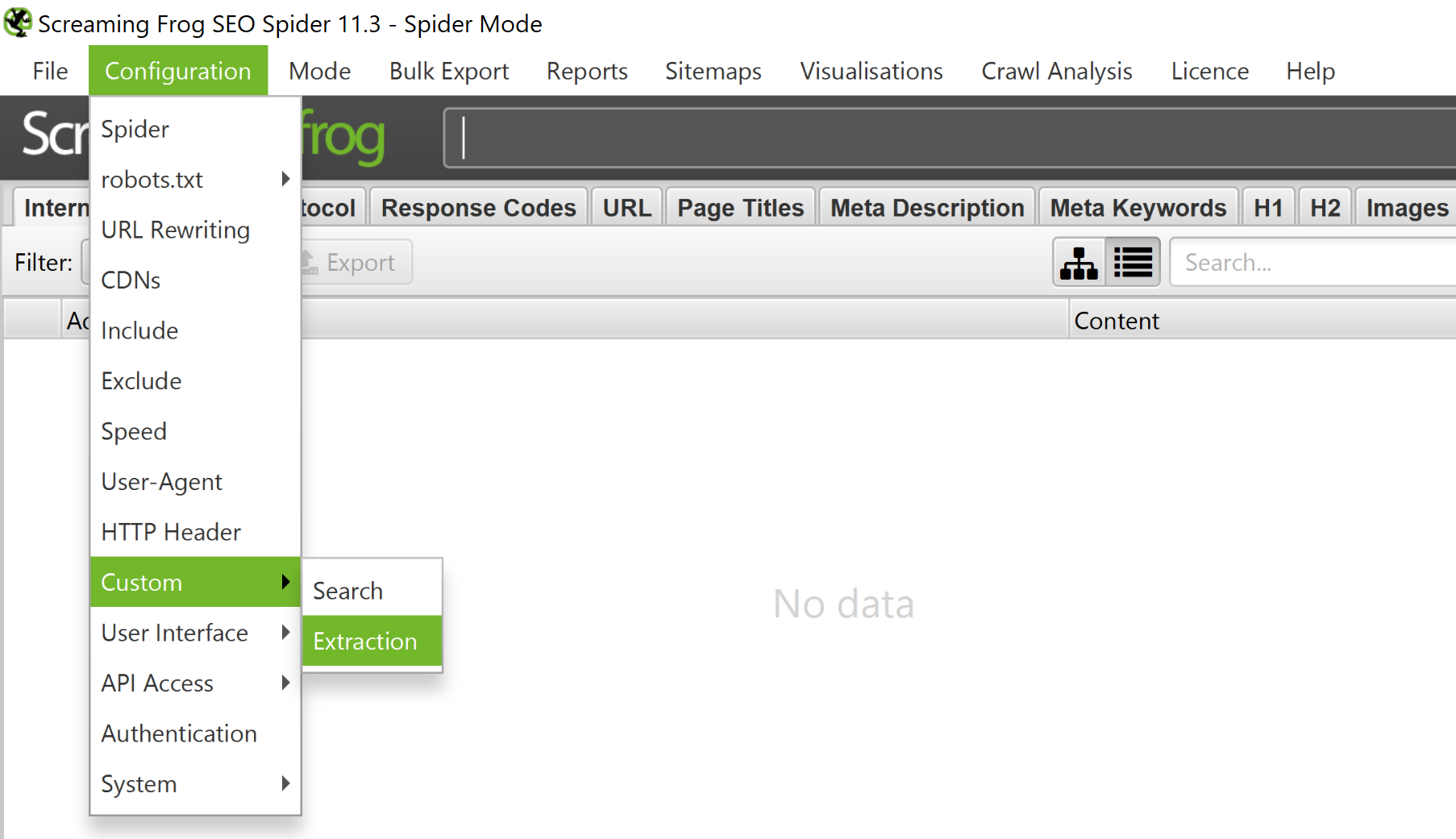
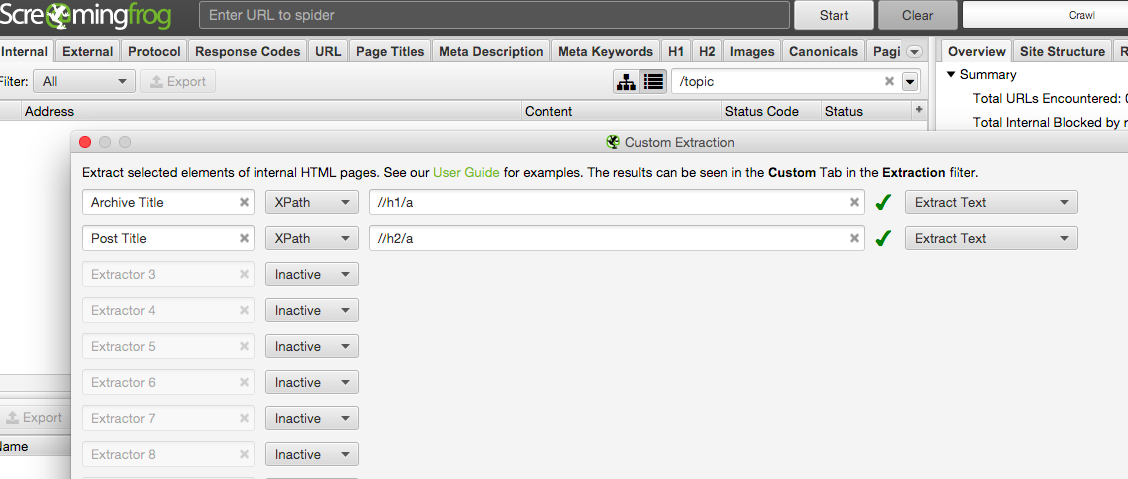
Add the Include and Exclude path patterns.
4) Crawl Your Website
The configuration is now complete. Run the crawl from any page that links the URL pattern in the ‘Include’ configuration. If your homepage does not have access to the blog category or product listing page, choose an alternative starting point, or the taxonomy page itself.
5) Analyze The Extraction
Once the crawl is complete, check the Custom tab in Screaming Frog and select the “Extraction” filter. You will see the crawled URLs, the taxonomy's Title/H1, and the titles of the posts or names of the products.
At the end of the row, you will find the number of articles (or products) included in that same page.
Export the file to assist analysis of your crawl to find duplicate taxonomies, little contents, similar URLs, etc.

6) Identify Actionable Elements
Once all the analysis is complete, finish the process according to your strategy.
As every project is unique with its own variables, goals, and resources, I cannot outline a 'one size fits all' approach.
I have listed some questions below to aid the achievement of your traffic and business goals, and identification of key elements:
- Did you find more taxonomies than posts?
- Did you find out that categories have a very limited number or no posts?
- Can you define these pages as duplicate content?
- Do taxonomies have similar names?
- Do archive pages have similar names, singular/plural versions, hyphens/non-hyphens?
- Can these taxonomies be merged?
- Are listing pages useful or can you potentially delete all of them?
- Are these pages helpful to define a site structure?
- Should you change the URL/Title according to the keyword research?
- Do the pages rank for any relevant query?
- Can you optimize the listing pages to bring more value and improve conversions and rankings?
- Connect Screaming Frog to Google Analytics and Google Search Console, do these pages get traffic? From which sources?
- Connect Screaming Frog to Majestic, Ahrefs or Moz, do these pages get relevant backlinks?
- Are the pages helpful to lead conversions?
- Should you add more products or content to successful listing pages?
- Should you add more stock to your product listing pages?
- How many “coming soon” and “out of stock” products can you find?
- Can you find products with little or no reviews and implement a relevant strategy?
- Can you demonstrate why and how changes can achieve your business goals?
Conclusions
An SEO audit is the first step for any business to ensure your website is aligned with your business goals.
Identifying, and removing, duplicate content is essential for keyword ranking, improving website quality, and turning newly attracted traffic into sales and leads.
References
An SEO’s guide to XPath
The Complete Guide to Screaming Frog Custom Extraction with XPath & Regex
Xpath cheatsheet
XPath Syntax
Custom Extraction in Screaming Frog: XPath and CSSPath
Web Scraping & Data Extraction Using The SEO Spider Tool