How Semrush Turns Traffic Data Into Traffic Intelligence
You may have been wondering where the traffic intelligence you see within our Traffic Analytics and Market Explorer tools comes from.
This article unveils the core processes—from raw data collection to ready-to-use insights visible within the tools.
Essentially, all the data goes through the four key stages:
- Data collection
- Data cleaning
- Data modeling
- Data delivery
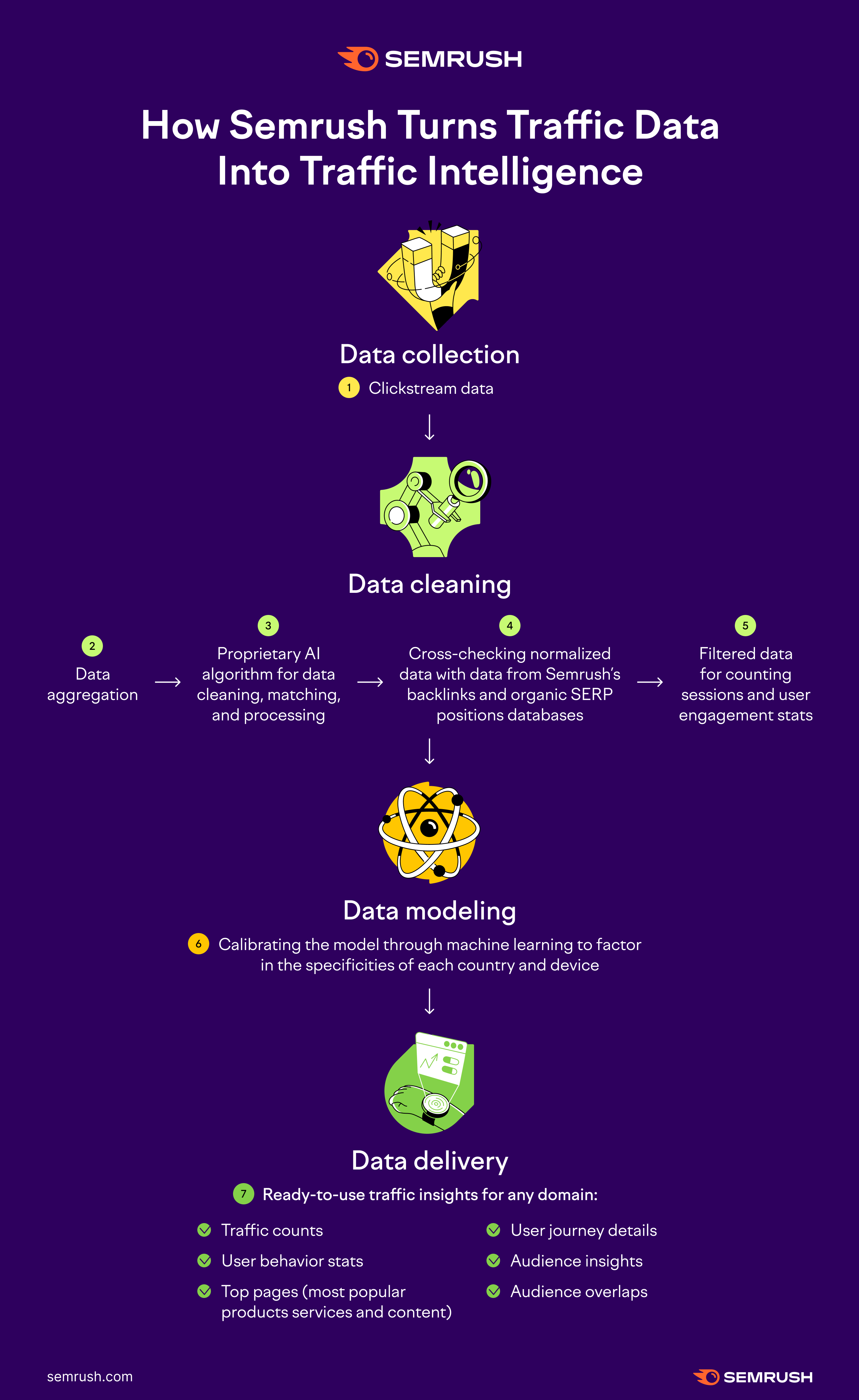
Data collection
We receive terabytes of data from a panel of various third-party data providers every one or two days. This is what’s called clickstream data—it offers an aggregated view of millions of real but anonymized internet users’ online journeys, following their online activity.
Clickstream data lets us identify general user behavior stats and trends.
Data Cleaning
All the data gets aggregated and aligned with a common format in the traffic analytics system.
Using our proprietary machine learning model, we clear data of various anomalies.
As our AI keeps learning, it begins to recognize patterns similar to the way a human brain does, turning our model into an extensive algorithm that can pinpoint anomalies and better separate questionable data from representative data.
We also cross-check the data with Semrush’s backlinks database and organic SERP positions database to see if it matches the specifics of each country and device.
Once the data is reviewed with our algorithm, we get a more realistic picture of generic users’ sessions, and this is the dataset around which we build our engagement metrics.
Data Modeling and Delivery
At this stage, we have a big data box where we store the clickstream and proprietary data.
Before we enter this data into our machine learning model, it goes through one more check. We normalize the data, taking the domain’s popularity into account, as well as “typical” user behavior across countries, demographics, devices, and various industries.
For instance, a user from the US who’s only using the web once a month will more likely visit Google (a popular domain) than the FDA’s website (a somewhat less visited domain), so we take out the part of users with very weak activity patterns in an effort to obtain more accurate data for both more popular and less visited websites.
This helps us input more meaningful data into our machine-learning model.
The algorithm goes through supervised learning, which means that our big data tech keeps enhancing and learning every day.
Daily and Weekly Traffic Data
Starting in September of 2023, Semrush now offers daily and weekly data in our Traffic Analytics tool. This enhanced feature comes along with the adoption of a new AI model that offers increased traffic granularity, accuracy, and stability.
While previously we only processed data on a monthly scale, the new model brings daily data processing. Processing data on a daily basis allows us to provide daily and weekly traffic metrics for competitor domains.
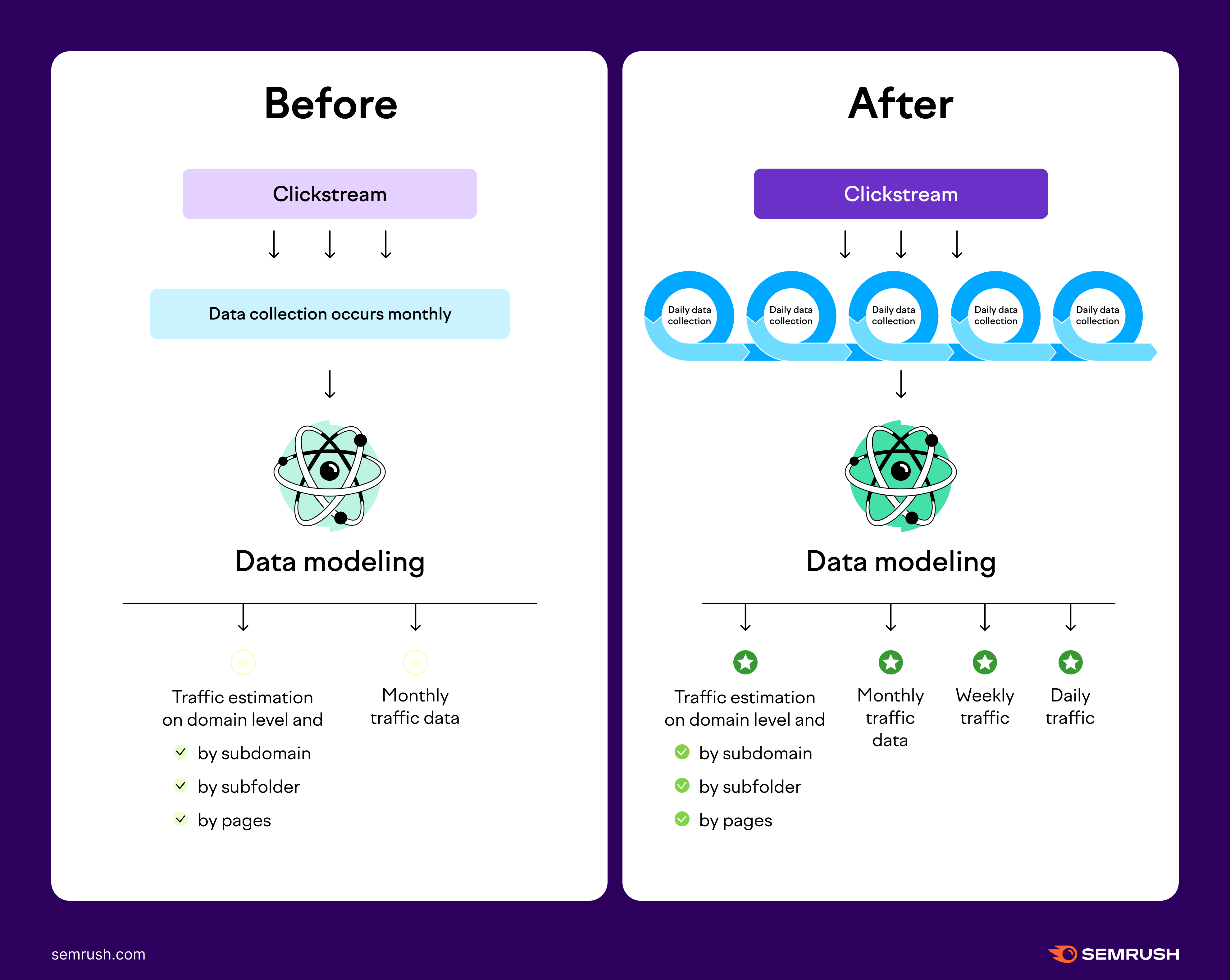
This update might impact stats across the Semrush Traffic Analytics reports, including historical data as far back as 2017. With this improved AI model offering higher-fidelity data, we are able to bring our prior estimates into sharper focus, which may cause some shifts in metrics.
On Semrush’s Traffic Data Coverage
With data quality, the sky’s the limit. So we are constantly working on adding new data to our tools, while our AI and big data tech keep learning and advancing their algorithms.
We’ve recently updated our data processing model for gathering traffic insights, which allowed us to expand our traffic data coverage by 20%.
Below, you can find out what changed exactly.

*Events represent the fact that a user visited a certain webpage.
**Sessions are a set of actions a user makes with a given website during a limited timeframe. In Semrush .Trends, we refer to sessions as visits.
- How Semrush Turns Traffic Data Into Traffic Intelligence
- How to Monitor Market Trends
- How to Evaluate a Prospective Partner with Semrush
- How to Quickly Overview a Niche
- How to Estimate a New Country’s Market Potential for Your Business
- How to Evaluate New Markets with Semrush .Trends
- How to Segment a Target Audience
- How to Analyze Competitor Content Strategies and Optimize Your Own
- How to Find Partners to Improve your Marketing Strategy
- How to Design and Deliver an Offer for Your Target Audience
- How to Use Daily Data to Uncover Key Market Insights