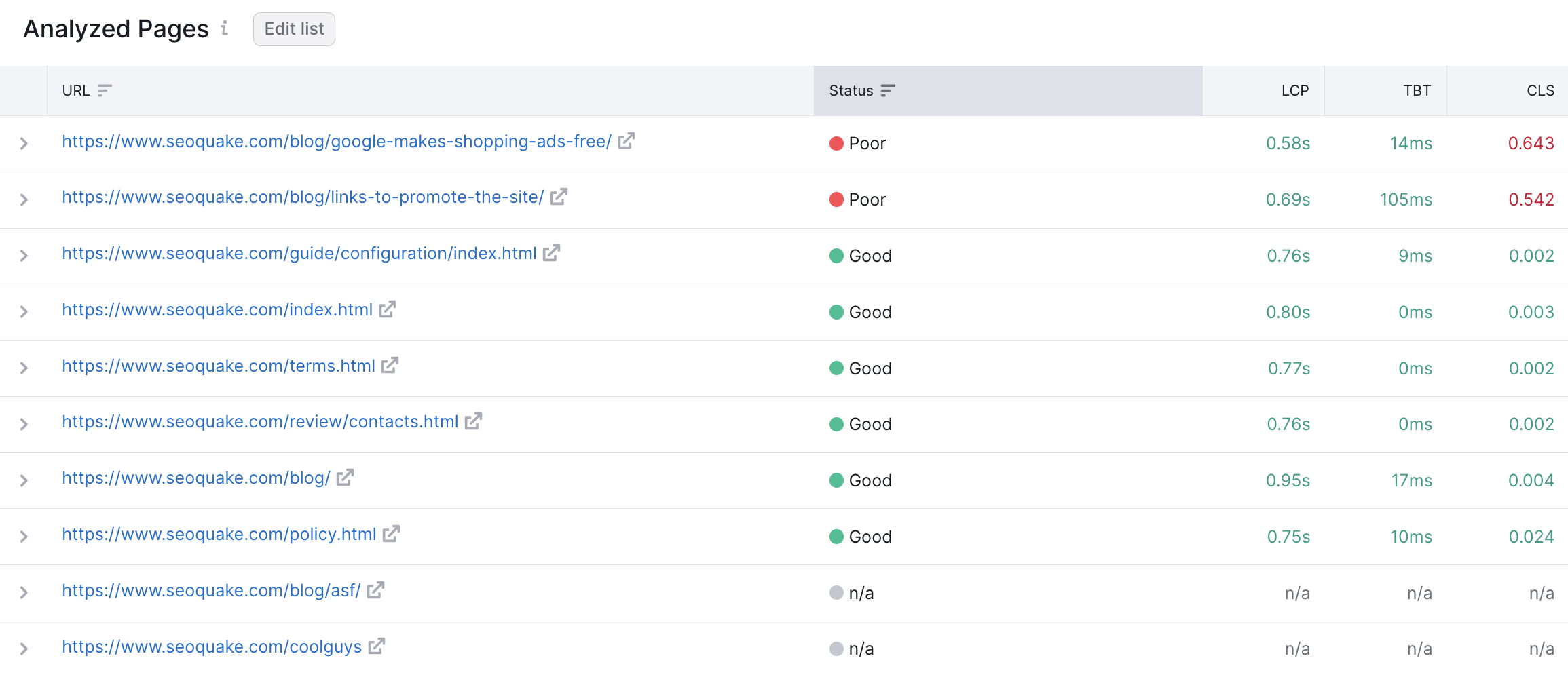
How Does Site Audit Select Pages to Analyze for Core Web Vitals?
Site Audit picks the first ten pages that have the ‘200 OK’ HTTP Status Code.
For the website crawl source, the system will most often select the main page and those pages that have links from the main page.
For crawling by sitemap and by the list of URLs, the system will take the first ten pages in a row, since they are considered the most crucial.
The list of analyzed pages doesn’t change with each crawl. It is fixed by the Site Audit algorithms in order to show historical trends.'. Please make sure that the pages are accessible for bots, otherwise they won’t be analyzed.
Can I Select the Pages Manually?
We have a functionality that allows you to select the pages that you want to be crawled. You can use it to audit the pages you are currently working on or the ones that are important for you at the moment, or different types of pages (e.g. main page, product page, category page) for an e-commerce site.
- Click on the “Edit list” button located at the top of the Analyzed Pages table.
- Add up to 10 URLs to the list in the pop-up window.
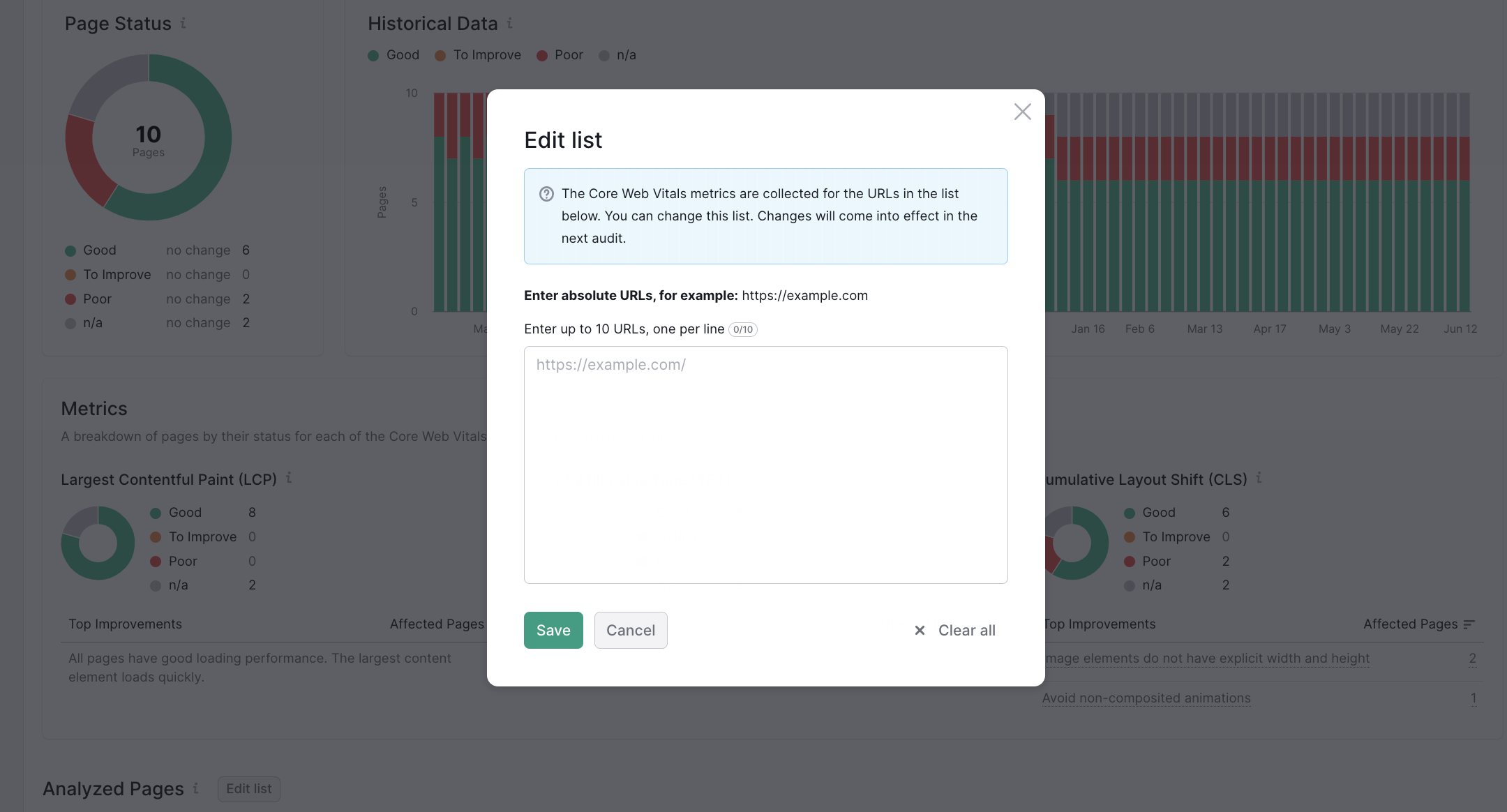
- Initiate the recrawl to see the new metrics*.
*Please note that if the page is not available, the historical data will be deleted for it.
- What Issues Can Site Audit Identify?
- How many pages can I crawl in a Site Audit?
- How long does it take to crawl a website? It appears that my audit is stuck.
- How do I audit a subdomain?
- Can I manage the automatic Site Audit re-run schedule?
- Can I set up a custom re-crawl schedule?
- How is Site Health Score calculated in the Site Audit tool?
- How Does Site Audit Select Pages to Analyze for Core Web Vitals?
- How do you collect data to measure Core Web Vitals in Site Audit?
- Why is there a difference between GSC and Semrush Core Web Vitals data?
- Why are only a few of my website’s pages being crawled?
- Why do working pages on my website appear as broken?
- Why can’t I find URLs from the Audit report on my website?
- Why does Semrush say I have duplicate content?
- Why does Semrush say I have an incorrect certificate?
- What are unoptimized anchors and how does Site Audit identify them?
- What do the Structured Data Markup Items in Site Audit Mean?
- Can I stop a current Site Audit crawl?
- Using JS Impact Report to Review a Page
- Configuring Site Audit
- Troubleshooting Site Audit
- Site Audit Overview Report
- Site Audit Thematic Reports
- Reviewing Your Site Audit Issues
- Site Audit Crawled Pages Report
- Site Audit Statistics
- Compare Crawls and Progress
- Exporting Site Audit Results
- How to Optimize your Site Audit Crawl Speed
- How To Integrate Site Audit with Zapier
- JS Impact Report